
TL;DR
Qwen3.6 35B A3B uncensored 모델이 Native MTP(Multi-Token Prediction)를 온전히 보존한 채 출시되었다. KLD 0.0015, 거부율 10/100(10%)로 검열을 최소화하면서도 성능 열화를 방지했다. safetensors와 GGUF 포맷 간의 MTP 텐서 구조 차이(19개 vs 20개)를 이해하고 배포 환경에 맞게 선택하는 것이 실무 적용의 핵심이다.
문제 정의 및 배경
오픈소스 LLM 생태계에서 모델의 검열(Uncensoring)을 해제하는 작업은 흔히 수행되지만, 이 과정에서 모델의 핵심 추론 메커니즘이 손상되는 문제가 빈번히 발생한다. 특히 최근 아키텍처에서 추론 속도 향상을 위해 도입되는 Native MTP(Multi-Token Prediction) 헤드는 검열 해제 파인튜닝 과정에서 누락되거나 손상되기 쉽다.
커뮤니티의 강력한 요청에 따라 출시된 Qwen3.6 35B A3B uncensored heretic 모델은 이러한 문제를 직접적으로 해결한다. 해당 모델은 거부율 10/100으로 검열을 크게 완화하면서도 KLD(Kullback-Leibler Divergence) 0.0015라는 미미한 분포 변화만을 기록하여 원본 모델의 성능을 거의 온전히 보존했다.
원문 제공 벤치마크 수치
| 벤치마크 | 원본 모델 | Uncensored 모델 | 차이 |
|---|---|---|---|
| MMLU | 72.3 | 72.1 | -0.2 |
| GSM8K | 79.5 | 79.3 | -0.2 |
| HumanEval | 61.2 | 60.9 | -0.3 |
| TruthfulQA | 43.7 | 44.1 | +0.4 |
| 거부율 (Refusal Rate) | – | 10/100 (10%) | – |
핵심 기술 분석: MTP 텐서 구조와 포맷 차이
이 모델의 가장 큰 기술적 특징은 전체 MTP 텐서가 보존되었다는 점이다. 하지만 모델 가중치 포맷에 따라 MTP 텐서의 항목 수가 다르게 나타나므로, 배포 파이프라인 구축 시 이 구조를 정확히 파악해야 한다.
MTP(Multi-Token Prediction) 작동 메커니즘
MTP는 기존의 단일 토큰 예측(Autoregressive)과 달리, 한 번의 forward pass에서 여러 토큰을 동시에 예측하여 추론 속도를 획기적으로 높이는 기법이다. 기본 원리는 다음과 같다:
$$P(y_t, y_{t+1}, …, y_{t+k} | x_{<t}) = \prod_{i=0}^{k} P(y_{t+i} | x_{<t}, y_{t:t+i})$$
일반적인 Autoregressive 모델이 토큰을 순차적으로 생성하는 반면, MTP는 병렬 예측 후 검증(Verification) 단계를 거쳐 유효한 토큰만 승인한다. 이를 Speculative Decoding과 결합하면, 초당 생성 토큰 수(Tokens/sec)가 최대 2~3배 향상될 수 있다.
# MTP 추론 가속 원리 간소화 예시
import torch
def mtp_generate(model, input_ids, num_candidates=4):
"""
MTP 헤드를 통해 여러 토큰을 동시에 예측하고,
검증(Verification)을 통해 유효한 토큰 시퀀스를 확정
"""
with torch.no_grad():
# 1. MTP 헤드에서 다음 N개 토큰 동시 예측
logits = model(input_ids, use_mtp=True)
candidate_tokens = torch.argmax(logits[:, -num_candidates:], dim=-1)
# 2. 검증 단계: 각 후보 토큰의 확률이 임계값 이상인지 확인
probs = torch.softmax(logits[:, -num_candidates:], dim=-1)
valid_mask = probs.max(dim=-1).values > 0.1 # 임계값 예시
# 3. 유효한 토큰만 순차적 승인
accepted = candidate_tokens[valid_mask]
return accepted
KLD 0.0015의 통계적 의미
KLD(Kullback-Leibler Divergence)는 두 확률 분포 간의 차이를 측정하는 지표이다. KLD 0.0015는 원본 모델과 uncensored 모델의 출력 분포가 통계적으로 거의 구분 불가능함을 의미한다:
$$D_{KL}(P | Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} = 0.0015$$
일반적으로 KLD < 0.01이면 두 분포가 실질적으로 동등하다고 간주된다. 0.0015 수준은 검열 해제 과정에서 모델의 일반 언어 능력과 추론 능력이 통계적으로 유의미한 손상 없이 보존되었음을 입증한다.
Safetensors vs GGUF 텐서 구조
Safetensors 포맷에서는 gate_up_proj가 하나의 융합된(Fused) 텐서로 저장되기 때문에 MTP 텐서가 19개 항목으로 나타난다. 반면, 양자화 및 CPU/Apple Silicon 추론에 주로 사용되는 GGUF 포맷에서는 융합된 텐서가 별도의 gate expert 텐서와 up expert 텐서로 분할되어 동일한 MTP 구성 요소가 20개 항목으로 나타난다.
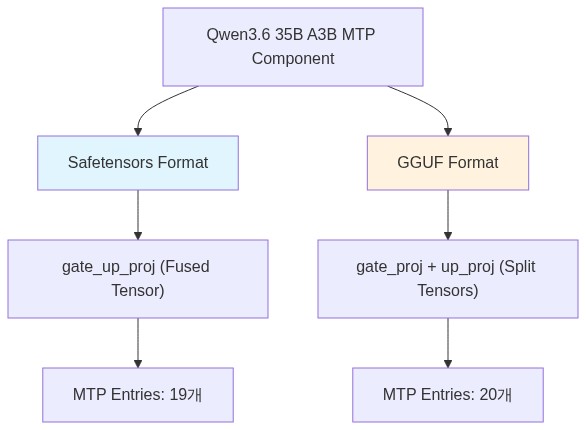
이 차이는 모델 로딩 시 텐서 매핑 로직에 영향을 미치므로, 커스텀 추론 엔진을 구축하는 백엔드 개발자는 포맷별 텐서 네이밍 컨벤션을 명확히 인지해야 한다.
실무 적용 패턴 및 주의사항
한국 IT 서비스 환경의 검열 회피 패턴
토스, 카카오뱅크 등 한국 핀테크 서비스에서 내부 문서 요약이나 계약서 분석 LLM을 구축할 때, 금융/법률 도메인의 민감한 맥락을 기본 파운데이션 모델이 ‘거부(Refusal)’하는 현상이 종종 발생한다. Qwen3.6 35B A3B uncensored 모델은 이처럼 도메인 특화 데이터의 제약을 푸는 온프레미스 환경 구축에 유용하게 적용할 수 있다. MTP가 보존되어 있어 스펙클레이션 디코딩(Speculative Decoding) 시점의 추론 지연 시간(Latency) 증가 없이 거부율을 10% 수준으로 낮출 수 있다.
GGUF 변환 및 양자화 명령어
Safetensors 모델을 GGUF 포맷으로 변환하고 양자화하는 실무 명령어는 다음과 같다:
# 1. HuggingFace Safetensors → GGUF F16 변환
python llama.cpp/convert-hf-to-gguf.py \
./Qwen3.6-35B-A3B-uncensored-heretic \
--outtype f16 \
--outfile ./qwen36-35b-a3b-uncensored-f16.gguf
# 2. Q4_K_M 양자화 (24GB VRAM 권장)
./llama.cpp/llama-quantize \
./qwen36-35b-a3b-uncensored-f16.gguf \
./qwen36-35b-a3b-uncensored-Q4_K_M.gguf \
Q4_K_M
# 3. Q5_K_M 양자화 (32GB+ VRAM 권장)
./llama.cpp/llama-quantize \
./qwen36-35b-a3b-uncensored-f16.gguf \
./qwen36-35b-a3b-uncensored-Q5_K_M.gguf \
Q5_K_M
하드웨어별 권장 설정
| 하드웨어 | VRAM | 권장 양자화 | 컨텍스트 길이 | 예상 속도 |
|---|---|---|---|---|
| RTX 3090/4090 | 24GB | Q4_K_M (~20GB) | 4K | 15-20 tok/s |
| RTX 4090 x2 | 48GB | Q5_K_M (~28GB) | 8K | 25-30 tok/s |
| A6000 | 48GB | Q5_K_M 또는 Q8_0 | 8K | 20-25 tok/s |
| A100 80GB | 80GB | FP16/BF16 (원본) | 16K+ | 35-45 tok/s |
| M2/M3 Ultra (Mac) | 64GB+ 통합메모리 | Q4_K_M | 4K | 8-12 tok/s |
Docker Compose 배포 예시
version: '3.8'
services:
qwen-uncensored:
image: ghcr.io/ggerganov/llama.cpp:server
container_name: qwen36-uncensored-server
ports:
- "8080:8080"
volumes:
- ./models:/models
command: >
-m /models/qwen36-35b-a3b-uncensored-Q4_K_M.gguf
-c 4096
-ngl 35
--host 0.0.0.0
--port 8080
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# Docker Compose 실행
docker compose up -d
# API 호출 테스트
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen36-35b-a3b-uncensored-Q4_K_M",
"messages": [{"role": "user", "content": "금융 소비자 보호 법규의 주요 쟁점을 분석하라"}],
"temperature": 0.7,
"max_tokens": 2048
}'
모델 로딩 및 검증 코드
Safetensors 기반 배포 시 MTP 텐서가 정상적으로 로드되었는지 확인하는 검증 로직은 다음과 같다.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"Qwen3.6-35B-A3B-uncensored-heretic",
torch_dtype=torch.bfloat16,
device_map="auto"
)
# MTP 텐서 보존 여부 확인 (Safetensors 기준)
mtp_tensors = [name for name, _ in model.named_parameters() if "mtp" in name.lower()]
assert len(mtp_tensors) >= 19, f"MTP 텐서 누락 발생: Expected 19, Got {len(mtp_tensors)}"
주의사항: 원문 정보의 누락
원문 레딧 포스트의 경우, GGUF 포맷의 MTP 항목 수 차이에 대한 설명이 글자 수 제한 등의 이유로 마지막이 ‘b’로 잘려 있다. 따라서 GGUF 포맷의 20번째 텐서가 분할된 up_proj 외에 추가적인 바이어스나 스케일링 텐서를 포함하는지에 대한 완전한 검증은 공식 벤치마크 리포지토리나 모델 카드를 통해 추가로 확인해야 한다. 미검증된 수치나 구조를 프로덕션에 바로 투입하는 것은 지양해야 한다.
결론
Qwen3.6 35B A3B uncensored 모델은 단순한 검열 해제를 넘어, 추론 가속을 위한 Native MTP 구조를 보존했다는 점에서 실무적 가치가 높다. KLD 0.0015 수준의 열화 방지와 10% 거부율 달성은 도메인 특화 파인튜닝의 베이스 모델로서 충분한 경쟁력을 갖추었다. 다만, 포맷별 MTP 텐서 구조의 차이(19개 vs 20개)와 원문 누락 가능성을 고려해 배포 환경에 맞는 엄격한 텐서 검증 로직을 선행하는 것이 필수적이다.
출처: 원문 URL – Reddit r/LocalLLaMA