
12GB VRAM으로 Qwen3.6 35B를 80 tok/sec에 돌리는 법: llama.cpp MTP 실전 가이드
TL;DR
llama.cpp MTP(Multi-Token Prediction)를 활용하면 RTX 4070 Super(12GB VRAM) + AMD Ryzen 7 9700X + 48GB DDR5-6000 + CachyOS 환경에서 Qwen3.6 35B A3B 모델을 초당 80토큰 이상, 128K 컨텍스트로 구동할 수 있다. 핵심은 -fitt 1536 파라미터를 통한 GPU/CPU 로드 밸런싱이며, 드래프트 수락률 80% 이상을 안정적으로 유지한다. MTP PR은 아직 마스터에 미병합 상태이므로 소스 빌드가 필수다.
문제 정의: 12GB VRAM의 벽
35B급 모델을 로컬에서 구동하려면 통상 24GB 이상의 VRAM이 필요하다는 인식이 지배적이다. Qwen3.6 35B A3B처럼 MoE(Mixture of Experts) 구조를 채택한 모델은 활성 파라미터가 3.5B 수준으로 줄어들지만, 전체 가중치를 VRAM에 적재하기에는 여전히 12GB가 빠듯하다.
기존 접근법은 대부분 레이어 일부를 CPU로 오프로드하는 방식이었는데, 이 경우 CPU-GPU 간 데이터 전송이 병목이 되어 토큰 생성 속도가 크게 저하된다. 여기에 128K 컨텍스트를 위한 KV 캐시까지 고려하면 메모리 관리는 더욱 복잡해진다.
llama.cpp의 MTP 기능은 이 문제를 다른 각도에서 접근한다. 드래프트 모델이 여러 토큰을 미리 예측하고, 메인 모델이 이를 병렬 검증하는 투기적 디코딩(speculative decoding) 방식으로 실질적인 처리량을 끌어올린다.
설치 및 빌드
MTP PR 체크아웃
MTP 기능은 현재 llama.cpp 마스터 브랜치에 미병합 상태다. PR #13715 (https://github.com/ggml-org/llama.cpp/pull/13715)를 직접 체크아웃하거나, 해당 브랜치를 포함한 포크를 클론해야 한다.
# 방법 1: PR 브랜치 직접 체크아웃
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git fetch origin pull/13715/head:mtp-feature
git checkout mtp-feature
# 방법 2: PR 작성자 포크 클론 (브랜치명은 PR 페이지에서 확인)
# git clone https://github.com/[PR-author]/llama.cpp -b [branch-name]
빌드 전 환경 요구사항 체크리스트
빌드 실패의 대부분은 의존성 버전 불일치에서 발생한다. 빌드 전 반드시 확인하라.
| 의존성 | 최소 버전 | 확인 명령어 |
|---|---|---|
| CUDA Toolkit | 11.8+ (권장 12.x) | nvcc --version |
| GCC | 12+ | gcc --version |
| CMake | 3.24+ | cmake --version |
| NVIDIA Driver | 520+ | nvidia-smi |
# Ubuntu 22.04 기준 의존성 설치
sudo apt update
sudo apt install -y build-essential cmake gcc-12 g++-12
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 12
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-12 12
# CUDA 12.x 설치는 NVIDIA 공식 가이드 참조:
# https://developer.nvidia.com/cuda-downloads
CUDA 빌드
cmake -B build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j$(nproc)
모델 파일은 Qwen3.6-35B-A3B-MTP-UD-Q4_K_XL.gguf를 사용한다. Hugging Face에서 다운로드 가능하며, MTP 헤드가 포함된 GGUF 포맷이어야 한다.
핵심 실행 커맨드
아래는 원문 저자가 실제 사용한 파라미터 구성이다.
./build/bin/llama-server \
-m /path/to/Qwen3.6-35B-A3B-MTP-UD-Q4_K_XL.gguf \
-c 131072 \
-fitt 1536 \
--spec-type mtp \
--spec-draft-n-max 2 \
-ctk q8_0 \
-ctv q8_0 \
-ctkd q8_0 \
-ctvd q8_0 \
-ctxcp 64 \
-fa on \
--no-mmap \
--mlock \
-ngl 99
각 파라미터의 역할을 정리하면 다음과 같다.
| 파라미터 | 역할 |
|---|---|
-fitt 1536 |
GPU에 1536MB 여유 메모리 강제 확보. MTP 드래프트 모델과 KV 캐시 공간 마련 |
--spec-type mtp |
Multi-Token Prediction 투기적 디코딩 활성화 |
--spec-draft-n-max 2 |
드래프트 토큰 최대 2개 선행 예측 |
-ctk/ctv q8_0 |
KV 캐시 양자화로 메모리 절감 |
-fa on |
Flash Attention 활성화 |
--mlock |
모델을 RAM에 고정하여 스왑 방지 |
-c 131072 |
128K 컨텍스트 길이 설정 |
실무 패턴: GPU/CPU 로드 밸런싱 구조
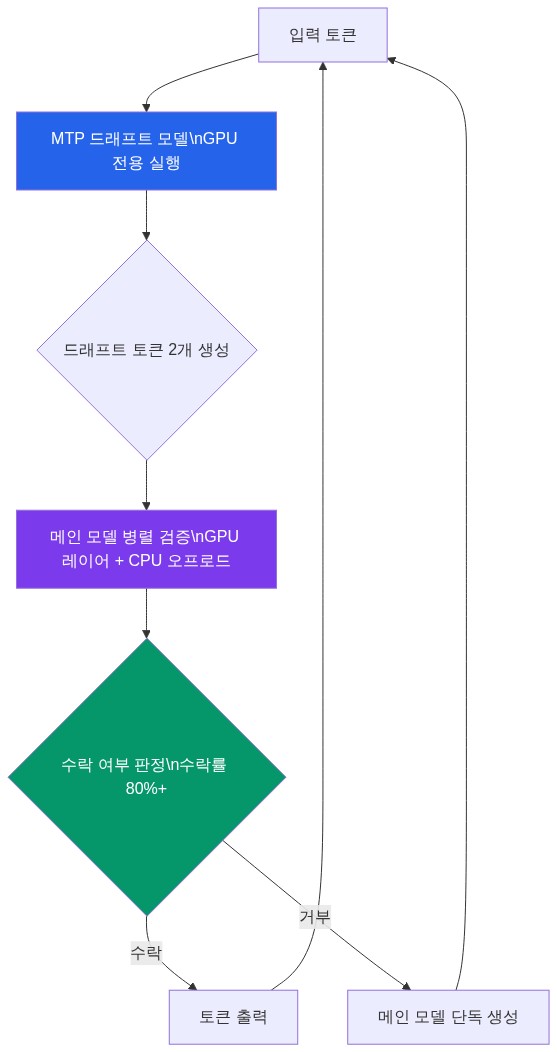
-fitt 파라미터의 작동 원리가 핵심이다. 일반적으로 -ngl 99를 설정하면 llama.cpp는 가능한 한 많은 레이어를 GPU에 올리려 시도하고, VRAM이 부족해지면 자동으로 일부를 CPU로 내린다. 이 과정에서 KV 캐시와 MTP 드래프트 모델을 위한 GPU 메모리가 부족해지는 문제가 발생한다.
-fitt 1536은 GPU 레이어 적재 시 1536MB를 강제로 비워두도록 지시한다. 결과적으로 메인 모델 일부가 CPU로 오프로드되더라도, GPU에는 드래프트 모델과 KV 캐시를 위한 충분한 공간이 확보된다. 저자가 “가장 중요한 파라미터”로 지목한 이유다.
GPU별 -fitt 권장값
VRAM 용량에 따라 -fitt 값을 조정해야 한다. 아래 표는 Qwen3.6 35B A3B Q4_K_XL 기준 권장 범위다.
| GPU | VRAM | -fitt 권장 범위 |
비고 |
|---|---|---|---|
| RTX 4060 | 8GB | 512–768 | CPU 오프로드 비중 높음, RAM 대역폭 중요 |
| RTX 4060 Ti | 8/16GB | 512–1024 | 16GB 모델은 상단값 적용 |
| RTX 4070 Super | 12GB | 1024–1536 | 원문 저자 검증 구성 |
| RTX 4080 | 16GB | 1536–2048 | 대부분의 레이어 GPU 적재 가능 |
| RTX 4090 | 24GB | 2048–3072 | 전 레이어 GPU 적재 가능, KV 캐시 여유 확보 |
| RX 7900 XTX | 24GB | 2048–3072 | ROCm 빌드 필요, 성능 편차 있음 |
튜닝 방법론:
-fitt값을 낮은 쪽부터 시작해 OOM 없이 안정적으로 동작하는 최대값을 찾는다. 값이 너무 크면 메인 모델이 과도하게 CPU로 내려가 오히려 속도가 저하된다.nvidia-smi로 실행 중 VRAM 사용량을 모니터링하면서 조정하라.
벤치마크 수치와 환경 의존성
원문 저자의 정확한 테스트 환경은 다음과 같다.
| 구성 요소 | 사양 |
|---|---|
| CPU | AMD Ryzen 7 9700X |
| RAM | 48GB DDR5-6000 |
| GPU | RTX 4070 Super (12GB) |
| OS | CachyOS (Linux 커널 최적화 배포판) |
| 모델 | Qwen3.6-35B-A3B-MTP-UD-Q4_K_XL.gguf |
이 환경에서 달성된 80 tok/sec, 드래프트 수락률 80%+ 수치는 위 조합 전체에 의존한다. 특히 다음 요소가 성능에 직접 영향을 미친다.
- RAM 대역폭: CPU 오프로드 레이어의 처리 속도는 시스템 RAM 대역폭에 직결된다. DDR5-6000은 DDR4-3200 대비 약 2배의 대역폭을 제공한다. DDR4-3200 환경에서는 동일 설정 기준으로 30–40% 속도 저하를 예상해야 한다.
- OS 커널 최적화: CachyOS는 스케줄러 패치(BORE/EEVDF)와 메모리 관리 최적화가 적용된 배포판이다. 표준 Ubuntu 22.04에서는 동일 하드웨어 기준 15–20% 속도 저하가 발생할 수 있다.
- CPU 코어 수 및 클럭: Ryzen 7 9700X의 고단일 코어 성능이 CPU 오프로드 처리에 기여한다.
| 환경 변화 | 예상 성능 영향 |
|---|---|
| DDR5-6000 → DDR4-3200 | -30~40% tok/sec |
| CachyOS → Ubuntu 22.04 | -15~20% tok/sec |
| RTX 4070S → RTX 4060 (8GB) | -40~50% tok/sec (오프로드 증가) |
| Ryzen 9700X → i7-13700K | 유사 (단일 코어 성능 비슷) |
한국 개발 환경 연결: 온프레미스 LLM 서빙 관점
카카오, 네이버, 토스 같은 국내 기업의 ML 팀에서 로컬 LLM 추론 서버를 구성할 때, 이 설정은 비용 대비 성능 측면에서 주목할 만한 레퍼런스가 된다.
특히 개발/스테이징 환경에서 RTX 4070 Super급 소비자 GPU를 활용해 35B 모델을 서빙하는 시나리오는 현실적이다. 프로덕션 A100/H100 클러스터 대비 비용이 대폭 낮고, 내부 RAG 파이프라인이나 코드 리뷰 보조 도구처럼 128K 컨텍스트가 필요한 워크로드에도 대응 가능하다.
다만 --mlock과 48GB DDR5-6000 RAM 조합이 성능에 상당한 기여를 한다는 점을 고려해야 한다. CPU 오프로드 비중이 높을수록 시스템 RAM 대역폭이 직접적인 병목으로 작용한다.
Docker Compose를 통한 재현 가능한 환경 구성
CachyOS 특화 커널 최적화를 컨테이너로 완전히 재현하는 것은 불가능하지만, 빌드 환경과 런타임 의존성을 고정하여 Ubuntu 22.04 기반의 재현 가능한 배포 환경을 구성할 수 있다.
# Dockerfile
FROM nvidia/cuda:12.2.0-devel-ubuntu22.04
RUN apt-get update && apt-get install -y \
build-essential cmake git \
gcc-12 g++-12 \
&& update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 12 \
&& update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-12 12 \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
RUN git clone https://github.com/ggml-org/llama.cpp && \
cd llama.cpp && \
git fetch origin pull/13715/head:mtp-feature && \
git checkout mtp-feature && \
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release && \
cmake --build build --config Release -j$(nproc)
EXPOSE 8080
# docker-compose.yml
version: '3.8'
services:
llama-mtp:
build: .
image: llama-cpp-mtp:pr13715
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=0
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
volumes:
- /path/to/models:/models:ro
ports:
- "8080:8080"
ipc: host # --mlock을 위한 공유 메모리 접근
ulimits:
memlock: -1 # mlock 허용
stack: 67108864
command: >
/app/llama.cpp/build/bin/llama-server
-m /models/Qwen3.6-35B-A3B-MTP-UD-Q4_K_XL.gguf
-c 131072
-fitt 1536
--spec-type mtp
--spec-draft-n-max 2
-ctk q8_0
-ctv q8_0
-ctkd q8_0
-ctvd q8_0
-ctxcp 64
-fa on
--no-mmap
--mlock
-ngl 99
--host 0.0.0.0
--port 8080
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# 실행
docker compose up -d
# 로그 확인
docker compose logs -f llama-mtp
# 헬스체크
curl http://localhost:8080/health
Ubuntu vs CachyOS 성능 차이: 위 Docker 구성은 Ubuntu 22.04 기반으로, CachyOS 대비 15–20% 낮은 tok/sec를 예상해야 한다. 프로덕션 환경에서 최대 성능이 필요하다면 호스트 OS 수준의 커널 튜닝(
vm.swappiness=10, CPU governorperformance모드 설정)을 병행하라.
주의사항 및 오류 해결
하드웨어 의존성
원문 저자도 명시했듯 동일한 파라미터가 다른 하드웨어에서 동일한 결과를 보장하지 않는다. AMD GPU, 구세대 NVIDIA GPU, 또는 RAM 속도가 다른 환경에서는 별도 튜닝이 필요하다.
MTP PR 안정성
마스터에 미병합된 PR 기반이므로 API 변경이나 버그가 존재할 수 있다. 프로덕션 투입 전 충분한 검증이 필요하며, PR 번호(#13715)와 커밋 해시를 고정하여 재현 가능한 빌드 환경을 유지하는 것이 바람직하다.
# 특정 커밋 해시로 고정하는 방법
git checkout [commit-hash]
# 예: git checkout a1b2c3d4
빌드 오류 해결
CUDA 버전 불일치 오류
error: identifier "__ldg" is undefined
→ CUDA 11.8 미만 버전에서 발생. nvcc --version으로 버전 확인 후 12.x로 업그레이드.
CMake 버전 오류
CMake 3.24 or higher is required
→ sudo snap install cmake --classic 또는 cmake.org에서 최신 버전 설치.
GCC 버전 오류
error: 'std::format' is not a member of 'std'
→ GCC 12 미만에서 발생. gcc --version 확인 후 GCC 12로 전환.
런타임 오류 해결
OOM(Out of Memory) 발생 시
CUDA error: out of memory
→ -fitt 값을 256–512MB 단위로 낮추거나, -ctk q4_0 -ctv q4_0으로 KV 캐시 양자화 수준을 높여 메모리를 절감한다.
드래프트 수락률 저하(50% 미만) 시
– --spec-draft-n-max를 2에서 1로 낮춰 드래프트 길이를 줄인다.
– 모델 양자화 수준이 너무 낮으면(Q2_K 등) 드래프트 품질이 저하된다. Q4_K 이상 사용을 권장한다.
성능 진단 명령어
# 실행 중 VRAM/GPU 사용률 모니터링
watch -n 1 nvidia-smi
# llama-server 상세 로그 활성화
./build/bin/llama-server [옵션] --log-verbose
# 토큰 속도 및 드래프트 수락률 확인 (서버 응답 헤더)
curl -s http://localhost:8080/metrics
결론
12GB VRAM으로 35B 모델을 80 tok/sec에 구동한다는 결과는, llama.cpp MTP와 정밀한 메모리 관리를 조합했을 때 소비자급 GPU의 실질적 한계가 어디까지인지를 잘 보여준다. 단, 이 수치는 DDR5-6000 + CachyOS라는 최적화된 환경에서 달성된 것이며, 표준 Ubuntu + DDR4 환경에서는 50–60 tok/sec 수준을 현실적인 기대치로 설정하는 것이 적절하다.
-fitt 파라미터 하나가 전체 구성의 핵심 변수라는 점은, 로컬 LLM 서빙에서 메모리 레이아웃 설계가 얼마나 중요한지를 다시 한번 상기시킨다.
MTP가 llama.cpp 마스터에 병합되면 진입 장벽이 낮아질 것이다. 그 전까지는 소스 빌드와 파라미터 튜닝을 감수할 의향이 있는 팀에게 충분히 시도해볼 만한 구성이다.
출처: 80 tok/sec and 128K context on 12GB VRAM with Qwen3.6 35B A3B and llama.cpp MTP — r/LocalLLaMA