
TL;DR
MEOW 이미지 포맷은 LSB 스테가노그래피를 활용해 AI 추론에 필요한 메타데이터를 픽셀 데이터 안에 직접 인코딩한다는 개념을 제안한다. PNG와 바이너리 호환되어 확장자만 바꾸면 기존 뷰어에서 열린다. 다만 원문 저장소에 자동 생성 메커니즘의 구체적 구현이 명시되어 있지 않고, 벤치마크와 실제 채택 경로도 부재해, 현 시점에서는 개념 증명(PoC) 수준으로 평가해야 한다.
배경: PNG와 JPEG의 메타데이터 문제
PNG(1995)와 JPEG(1992)는 설계 당시부터 인간의 시각 품질 최적화를 목표로 했다. 두 포맷 모두 EXIF, XMP, iTXt 청크 등 메타데이터 슬롯을 제공하지만, 실제 AI 워크플로우에서는 두 가지 구조적 문제가 발생한다.
첫째, 메타데이터 유실이다. SNS 업로드, 이미지 리사이징, CDN 파이프라인을 거치면 EXIF 블록은 대부분 제거된다. 카카오나 네이버 같은 플랫폼의 이미지 서빙 파이프라인을 생각해 보면, 원본 EXIF를 보존하는 경우는 오히려 예외적이다.
둘째, 표현력 한계이다. 기존 메타데이터 스키마는 카메라 설정, 저작권 정보 등 촬영 맥락 중심으로 설계되어 있다. AI 모델이 추론 전에 필요로 하는 구조적 정보를 표준적으로 담을 수 있는 슬롯이 없다.
MEOW는 이 두 문제를 “메타데이터를 별도 필드가 아닌 픽셀 안에 숨긴다”는 방식으로 우회하려 한다.
핵심 메커니즘: LSB 스테가노그래피 기반 AI 메타데이터 인코딩
LSB 인코딩 원리
RGB 채널 각 픽셀은 8비트(0~255)로 표현된다. 최하위 비트(Least Significant Bit)를 변경해도 색상값은 최대 1만큼만 달라지므로 육안으로는 식별이 불가능하다. MEOW는 이 비트 공간에 구조화된 AI 메타데이터를 삽입한다는 아이디어를 제안한다.
아래 코드는 LSB 인코딩의 원리를 설명하기 위한 예시이며, MEOW 저장소의 실제 구현 코드와 다를 수 있다. 실제 구현은 GitHub 저장소에서 직접 확인하길 권장한다.
def encode_lsb(pixel_value: int, bit: int) -> int:
"""픽셀의 LSB에 단일 비트를 인코딩."""
return (pixel_value & 0xFE) | (bit & 0x01)
def embed_metadata(image_array, metadata_bits: list[int]):
"""
image_array: H x W x C numpy array (uint8)
metadata_bits: 삽입할 비트 시퀀스
"""
flat = image_array.flatten()
if len(metadata_bits) > len(flat):
raise ValueError("메타데이터가 이미지 용량을 초과합니다.")
for idx, bit in enumerate(metadata_bits):
flat[idx] = encode_lsb(int(flat[idx]), bit)
return flat.reshape(image_array.shape)
이론적 활용 가능성: AI 특화 데이터 유형
⚠️ 주의: 이 섹션은 LSB 레이어에 삽입 가능한 데이터 유형의 이론적 가능성을 설명한다. 원문 GitHub 저장소에는 아래 항목들이 자동으로 생성·삽입된다는 구현이 명시되어 있지 않다. 저자의 README 기술과 실제 코드 사이의 간극이 존재하므로, 아래 내용은 포맷 설계 의도의 해석으로 읽어야 한다.
LSB 공간에 이론적으로 삽입할 수 있는 AI 관련 데이터 유형은 다음과 같다.
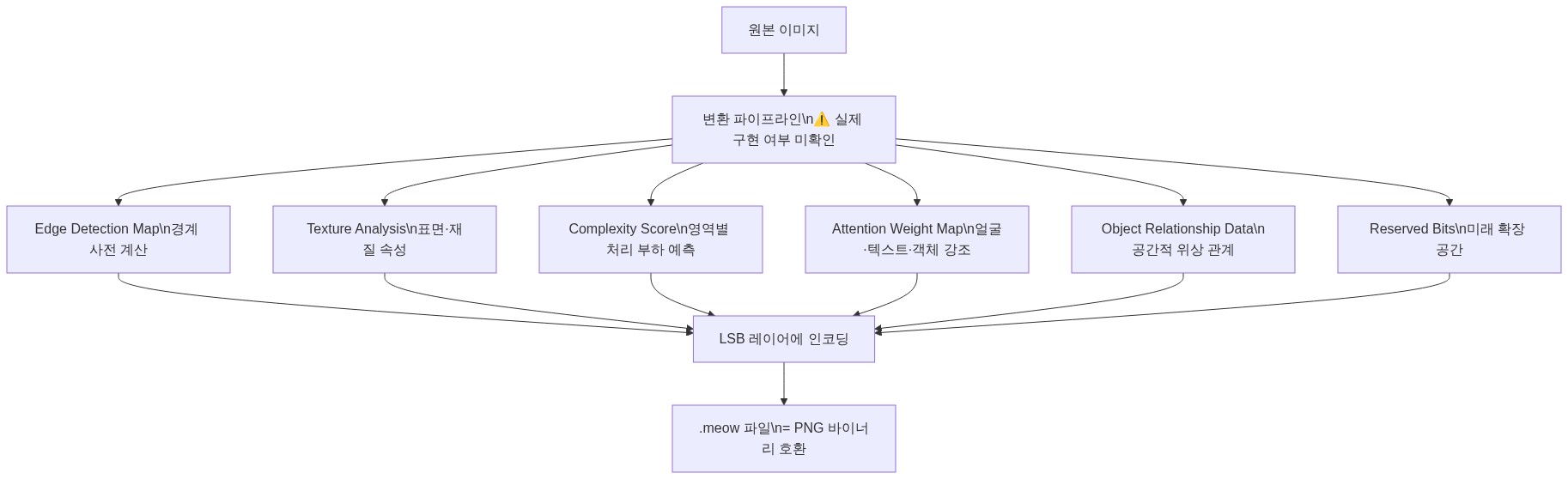
이 데이터 유형들이 실제로 자동 생성되는지, 사용자가 직접 삽입해야 하는지, 아니면 미래 로드맵인지는 현재 공개된 저장소만으로는 확인할 수 없다.
PNG 호환성 구조
MEOW 파일은 PNG 시그니처(\x89PNG\r\n\x1a\n)와 청크 구조를 그대로 유지한다. 픽셀 데이터(IDAT 청크) 내부 LSB에만 추가 정보가 담기므로, 확장자를 .png로 변경하면 일반 이미지 뷰어에서 정상 렌더링된다.
지금 당장 시도해보기
MEOW 저장소를 직접 클론해 실험해볼 수 있다. 단, 현재 공개된 코드는 PoC 수준이므로 프로덕션 사용은 권장하지 않는다.
# 저장소 클론
git clone https://github.com/Kuberwastaken/meow
cd meow
# 의존성 설치 (저장소의 requirements.txt 기준)
pip install -r requirements.txt
# 실행 방법은 저장소의 README를 참고
# pip install meow 형태의 패키지 배포는 현재 미확인
현재 상태: PyPI 패키지(
pip install meow) 또는 Docker 이미지 형태의 배포는 저장소에서 확인되지 않는다. CLI 인터페이스의 완성도도 README만으로는 파악하기 어렵다. 직접 실험 전에 저장소의 최신 커밋과 이슈 트래커를 먼저 확인하길 권장한다.
정량적 검토: 측정해야 할 것들
MEOW의 실용성을 판단하려면 다음 지표들이 실측되어야 한다. 현재 저장소에는 이 중 어느 것도 공개된 벤치마크가 없다.
LSB 인코딩 오버헤드 (추정 실험)
아래는 순수 LSB 비트 조작의 연산 비용을 가늠하기 위한 참고 실험이다. MEOW 고유의 수치가 아니라, 동일한 원리를 적용했을 때 예상되는 오더(order of magnitude)를 보여준다.
import numpy as np
import time
# 1000x1000 RGB 이미지 (300만 픽셀)
image = np.random.randint(0, 256, (1000, 1000, 3), dtype=np.uint8)
metadata_bits = np.random.randint(0, 2, image.size).tolist()
start = time.perf_counter()
flat = image.flatten()
for idx, bit in enumerate(metadata_bits):
flat[idx] = (int(flat[idx]) & 0xFE) | (bit & 0x01)
result = flat.reshape(image.shape)
elapsed = time.perf_counter() - start
print(f"인코딩 시간: {elapsed:.3f}초 (순수 Python, 최적화 없음)")
# 예상: 수 초 단위 → numpy 벡터화 시 수십 ms 수준으로 단축 가능
실측이 필요한 항목:
| 측정 항목 | 측정 방법 | 현재 공개 여부 |
|---|---|---|
| 인코딩 시간 (1MP 기준) | time.perf_counter() 전후 측정 | ❌ 미공개 |
| 메타데이터 추출 시간 | 디코딩 루프 벤치마크 | ❌ 미공개 |
| 추론 시간 단축 효과 | 전처리 포함/미포함 모델 추론 비교 | ❌ 미공개 |
| 파일 크기 변화 | 원본 PNG vs .meow 바이트 비교 | ❌ 미공개 |
| JPEG 재압축 후 데이터 유실률 | 품질 설정별(Q=95/80/60) 비트 오류율 | ❌ 미공개 |
손실 압축 내성 실험 (개념 검증)
LSB가 손실 압축에 얼마나 취약한지는 간단히 확인할 수 있다.
from PIL import Image
import io
import numpy as np
def lsb_survival_rate(original_array, compressed_array):
"""JPEG 압축 후 LSB 생존율 계산."""
orig_lsb = original_array.flatten() & 0x01
comp_lsb = compressed_array.flatten() & 0x01
return np.mean(orig_lsb == comp_lsb)
# 테스트: PNG → JPEG(Q=95) → 다시 읽기
img = Image.open("test.png")
arr_orig = np.array(img)
buf = io.BytesIO()
img.save(buf, format="JPEG", quality=95)
buf.seek(0)
arr_compressed = np.array(Image.open(buf))
print(f"Q=95 JPEG 후 LSB 생존율: {lsb_survival_rate(arr_orig, arr_compressed):.1%}")
# 예상: ~50% (사실상 랜덤 노이즈 수준 → 데이터 완전 소실)
이 실험은 MEOW의 근본적 제약을 드러낸다. JPEG 재압축 한 번으로 LSB 데이터는 사실상 복구 불가능한 수준으로 손상된다. “이미지 크기 증가 없음”이라는 원문의 주장도, PNG 무손실 저장을 전제로 한 것인지 여부가 명확히 기술되어 있지 않아 별도 검증이 필요하다.
한국 개발 환경 연결 포인트
토스의 이미지 분류 파이프라인이나 네이버 클로바의 OCR 전처리 단계를 예로 들면, 현재는 모델 추론 전 엣지 검출이나 관심 영역(ROI) 계산을 런타임에 수행한다. MEOW가 실제 채택된다면 이 전처리 비용을 업로드 시점으로 이전(shift-left)할 수 있다는 논리는 성립한다.
⚠️ 검증 필요: 위 사례는 일반적인 AI 이미지 파이프라인 구조를 바탕으로 한 추론이다. 토스·네이버 클로바·카카오의 실제 파이프라인 구성, MEOW 도입 시 실질적 레이턴시 개선 여부는 공개된 자료만으로 확인할 수 없으며, 별도 검증이 필요하다.
다만 이들 플랫폼의 이미지 파이프라인은 대부분 JPEG 재압축 또는 WebP 변환을 수행하는데, 이 과정에서 LSB 레이어가 파괴된다는 점은 치명적 제약이다. 이 문제가 해결되지 않으면 한국 주요 플랫폼 환경에서의 실용성은 매우 제한적이다.
한계: 개념과 실제 사이
| 항목 | 현황 |
|---|---|
| 벤치마크 | 추론 속도 개선 수치 미제시 |
| 압축 내성 | JPEG 재압축 시 LSB 데이터 소실 |
| 채택 선례 | HEIF, AVIF, JPEG XL 등 우수한 포맷도 채택에 수년 소요 |
| 구현 완성도 | 공개 저장소 기준 PoC 수준 |
| 자동 생성 기능 | README와 실제 구현 간 간극 미확인 |
| 배포 방식 | PyPI/Docker 미확인, CLI 완성도 불명확 |
LSB 스테가노그래피는 무손실 전송 환경에서만 데이터를 보존한다. 현실의 이미지 유통 경로—SNS 재업로드, CDN 트랜스코딩, 스크린샷—에서 LSB가 살아남는다는 주장은 검증이 필요하다. 저자는 “screenshot-and-repost cycles에서도 생존한다”고 기술하지만, 이는 PNG→PNG 무손실 경로에 한정된 주장으로 보이며, 실측 데이터가 없다.
포맷 채택 문제도 있다. JPEG XL은 기술적 우위에도 불구하고 Chrome에서 한때 지원이 철회되었다. 새 포맷의 생태계 진입 장벽은 기술 완성도만으로 해결되지 않는다.
결론
MEOW 이미지 포맷은 AI 파이프라인의 실제 불편함—메타데이터 유실, 전처리 중복—을 포맷 레벨에서 해결하려는 시도로 아이디어 자체는 주목할 만하다. LSB 기반 AI 메타데이터 인코딩이라는 접근은 기존 PNG 인프라와의 호환성을 유지하면서 확장성을 확보하는 현실적인 설계 선택이다.
그러나 손실 압축 환경에서의 데이터 내성, 실측 성능 데이터 부재, 채택 경로 미비, 그리고 README와 실제 구현 사이의 간극이라는 네 가지 문제가 해결되지 않으면 흥미로운 주말 프로젝트 이상이 되기 어렵다. AI 이미지 처리 파이프라인을 설계하는 엔지니어라면, 이 포맷의 아이디어를 참고해 자체 메타데이터 사이드카 포맷이나 IDAT 청크 확장 방식을 검토하는 것이 더 실용적인 접근일 수 있다.
출처: https://github.com/Kuberwastaken/meow