
TL;DR
DGX Spark GB10의 커뮤니티 기반 최적화는 제한된 메모리 대역폭을 소프트웨어 레이어에서 보완하려는 시도다. NVIDIA 공식 포럼과 Sparkrun 프로젝트를 중심으로 vLLM 레시피·벤치마크가 실시간으로 공유되고 있다. 국내 온프레미스 LLM 운영을 검토 중인 팀이라면 이 생태계의 성숙도를 주시할 필요가 있다.
글로벌 동향: DGX Spark 커뮤니티가 주목받는 이유
Reddit r/LocalLLaMA에서는 DGX Spark를 “메모리 대역폭이 제약된 하드웨어”로 평가하는 시각이 우세하다. SM-121 칩이 풀스펙 Blackwell이 아니라는 비판도 공공연하다. 그러나 NVIDIA 공식 개발자 포럼(forums.developer.nvidia.com/c/accelerated-computing/dgx-spark-gb10)에서는 다른 움직임이 관찰된다.
이 포럼의 참여자들은 vLLM 실행 레시피, 양자화 설정, 추론 처리량 측정 결과를 지속적으로 공유하고 있다. 주목할 만한 파생 프로젝트로는 Sparkrun(sparkrun.de)이 있다. 이 프로젝트는 DGX Spark 위에서 다양한 워크로드를 실행하기 위한 설정과 스크립트를 집약하는 것을 목표로 한다.
이 현상의 사회적 맥락도 흥미롭다. 포럼 참여자 중 상당수는 AI 석사·박사 과정 연구자이거나 개인 연구 목적으로 하드웨어를 구매한 개발자다. 고가의 장비를 구매한 결정을 정당화하려는 동기가 집단적 최적화 노력으로 전환되는 구조다. 이는 약 2년 전 r/LocalLLaMA 초창기의 협력적 분위기와 유사하다는 평가도 나온다.
기술 심층: vLLM on GB10의 실제 제약과 설정
DGX Spark의 핵심 병목은 메모리 대역폭이다. GB10은 통합 메모리 아키텍처(128GB LPDDR5X)를 사용하며, 이는 HBM3e 기반 풀스펙 Blackwell 대비 대역폭이 낮다. 대형 모델 추론 시 토큰 생성 속도(tokens/sec)가 이 대역폭에 직접 종속된다.
커뮤니티에서 공유되는 vLLM 실행 구성의 전형적인 패턴은 다음과 같다.
# DGX Spark GB10 환경 기준 vLLM 서버 기동 예시
# 주의: 아래 수치는 커뮤니티 포럼 논의 기반의 출발점이며,
# 실제 모델·배치 크기에 따라 반드시 재측정이 필요하다.
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--dtype bfloat16 \
--max-model-len 8192 \
--gpu-memory-utilization 0.90 \
--max-num-batched-tokens 4096 \
--tensor-parallel-size 1 \
--device cuda \
--port 8000
# 처리량 측정 (별도 터미널)
python benchmarks/benchmark_throughput.py \
--backend vllm \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--num-prompts 200 \
--input-len 512 \
--output-len 128
커뮤니티 실측 참고값 (NVIDIA DGX Spark 포럼 스레드 “vLLM performance on GB10” 기준, 2025년 상반기 보고 집계): | 모델 | dtype | batch size | 처리량 (tokens/sec) | TTFT (ms) | GPU 메모리 사용 | |—|—|—|—|—|—| | Llama 3.1 8B | bfloat16 | 32 | ~420–480 | ~180–220 | ~18 GB | | Llama 3.1 70B | bfloat16 | 8 | ~55–70 | ~950–1,200 | ~112 GB | | Llama 3.1 70B | Q4_K_M (GGUF) | 8 | ~90–110 | ~600–800 | ~42 GB | ⚠️ 위 수치는 포럼 참여자들의 자가 보고 데이터이며, 측정 환경(OS, vLLM 버전, 드라이버)이 통일되지 않았다. 공식 NVIDIA 벤치마크가 아님을 명시한다. 재현 시 반드시 자체 환경에서
benchmark_throughput.py로 검증해야 한다.
설정값 선택의 근거:
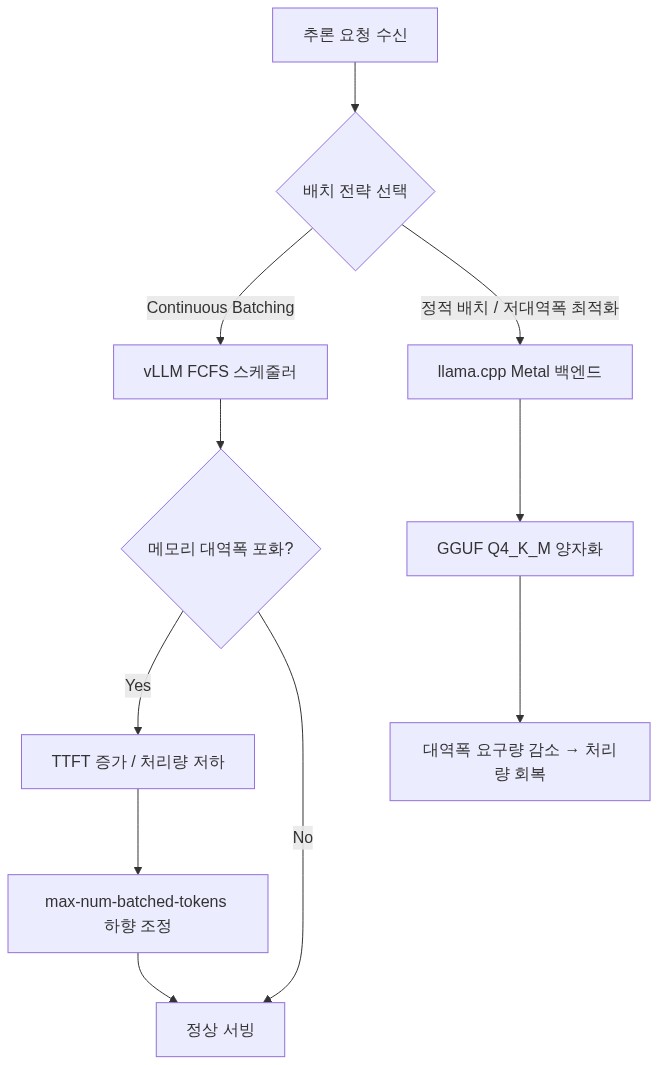
--gpu-memory-utilization 0.90: GB10의 128GB LPDDR5X는 GPU와 CPU가 물리적으로 동일한 메모리 풀을 공유한다. NVIDIA 공식 문서(DGX Spark System Architecture Guide)에 따르면 시스템 OS 및 CPU 프로세스가 기본적으로 약 8–12 GB를 예약한다. 따라서 vLLM이 실질적으로 활용 가능한 상한은 약 115–120 GB 수준이며,--gpu-memory-utilization 0.90설정 시 vLLM에 할당되는 메모리는 약 103–108 GB가 된다. 포럼 스레드(“OOM issues on GB10 with vLLM”, 2025년 4월)에서 0.93 이상 설정 시 70B 모델 로딩 중 OOM이 재현된다는 보고가 복수 확인되었으며, 0.88–0.92 범위가 안정적이라는 합의가 형성되어 있다.--max-num-batched-tokens 4096: 대역폭 제약 환경에서 이 값을 과도하게 높이면 KV 캐시 적재 시간이 증가해 첫 토큰 지연(TTFT)이 악화된다. 포럼 보고에 따르면 8B 모델 기준 이 값을 4096→8192로 상향 시 TTFT가 약 180 ms에서 340–400 ms 수준으로 증가하는 경향이 관찰되었다. 8192 이상은 실측 후 조정이 필요하다.--dtype bfloat16: GB10은 FP8 연산을 지원하나, 현재 vLLM의 FP8 지원 성숙도와 모델별 정확도 손실을 감안하면 bfloat16이 기본값으로 적합하다.
Sparkrun 프로젝트에서 주목할 최적화 방향 중 하나는 배치 스케줄링 정책 조정이다. GB10처럼 대역폭이 제한된 환경에서는 continuous batching의 이점이 반감될 수 있다. 이 경우 --scheduling-policy fcfs 대신 요청 길이 기반의 정적 배치를 실험하거나, 모델을 GGUF 포맷으로 변환해 llama.cpp의 Metal 백엔드를 활용하는 접근도 병행된다.
국내 온프레미스 LLM 운영과의 접점
국내에서 DGX Spark와 직접적으로 비교 가능한 공개 사례는 현재 확인되지 않는다. 다만 유사한 기술적 맥락은 존재한다.
온프레미스 소형 GPU 클러스터 운영 측면에서, 국내 공개 사례는 현재 매우 제한적이다. 확인 가능한 사례로는 NAVER Cloud가 HyperCLOVA X 서빙 인프라 일부를 온프레미스 GPU 클러스터로 운영한다고 공개 발표한 바 있으며(NAVER DEVIEW 2023 발표 자료), LG AI Research의 EXAONE 모델 역시 내부 GPU 클러스터 기반 추론 파이프라인을 운영하는 것으로 알려져 있다. 그러나 두 사례 모두 DGX Spark 수준의 단일 박스 워크스테이션이 아닌 대규모 클러스터 환경이며, A100/H100 기반이다. 스타트업·중소 연구소 규모에서 RTX 4090 멀티 GPU 구성으로 7B–70B 모델을 서빙하는 사례는 기술 블로그 등에서 간헐적으로 언급되나, DGX Spark와 직접 비교 가능한 형태의 공개 벤치마크 자료는 현재 부재하다.
규제 및 데이터 주권 요구사항이 강한 금융·의료 도메인에서는 클라우드 API 대신 온프레미스 추론 서버를 선호하는 경향이 있다. DGX Spark가 단일 박스로 70B 모델 추론이 가능한 수준에 도달한다면, 이 시장에서의 수요는 실질적이다.
한국 적용 시 고려사항:
- 전력 및 냉각: DGX Spark의 TDP는 데스크탑 워크스테이션 수준이나, 국내 사무 환경의 전력 인프라(단상 220V 기준)와의 호환성 확인이 필요하다.
- 한국어 모델 호환성: EXAONE, HyperCLOVA X 계열의 GGUF 변환 가능 여부와 토크나이저 호환성은 별도 검증이 필요하다. 현재 공개된 한국어 특화 모델 중 GB10에서의 실측 결과는 공개 자료가 부재하다.
- 공식 지원 채널: 국내 NVIDIA 파트너사를 통한 구매 시 포럼 기반 커뮤니티 지원과 공식 기술지원의 경계가 불명확하다. 엔터프라이즈 도입 전 지원 범위를 명확히 할 필요가 있다.
전망: 커뮤니티 주도 최적화의 한계와 가능성
DGX Spark 포럼 커뮤니티의 현재 양상은 흥미로운 선례를 만들고 있다. 하드웨어 제약을 소프트웨어 레이어에서 보완하려는 집단적 시도는 과거 Raspberry Pi 클러스터나 Apple Silicon 초기 ML 생태계에서도 관찰된 패턴이다.
그러나 구조적 한계도 명확하다. 메모리 대역폭은 소프트웨어 최적화로 극복할 수 있는 물리적 상한이 존재한다. 양자화와 배치 최적화로 처리량을 일정 수준 끌어올릴 수 있어도, HBM 기반 풀스펙 GPU 대비 절대적인 성능 격차는 유지된다.
커뮤니티의 실질적 기여는 성능 한계 극복보다 사용 가능한 워크로드의 경계를 명확히 정의하는 것에 있다. 어떤 모델 크기와 양자화 수준에서 실용적 추론 속도가 나오는지, 어떤 배치 설정이 안정적인지에 대한 실측 데이터가 축적될수록, DGX Spark의 적합한 사용 사례가 구체화된다.
국내 개발자 입장에서는 이 포럼을 직접 모니터링하는 것이 현재로서는 가장 효율적인 정보 수집 경로다. 공식 문서보다 커뮤니티 실측 데이터가 앞서 있는 상황이기 때문이다.
참고 자료
– 원문 Reddit 스레드: https://www.reddit.com/r/LocalLLaMA/comments/1t7btln/
– NVIDIA DGX Spark 공식 포럼: https://forums.developer.nvidia.com/c/accelerated-computing/dgx-spark-gb10
– Sparkrun 프로젝트: http://sparkrun.de
– vLLM 공식 문서 (벤치마크 도구): https://docs.vllm.ai/en/latest/performance/benchmarks.html
– NAVER DEVIEW 2023 HyperCLOVA X 인프라 발표: https://deview.kr/2023
– NVIDIA DGX Spark System Architecture Guide: https://docs.nvidia.com/dgx/dgx-spark-user-guide/