TL;DR
AI2의 새로운 MoE 모델 EMO는 문서 수준 라우팅(document-level routing)을 핵심 메커니즘으로 채택해, 전문가(Expert)가 토큰 단위가 아닌 도메인 단위로 특화된다. 활성 파라미터 1B, 전체 파라미터 14B 규모로, 전문가들이 health·news 등 의미론적 도메인을 중심으로 클러스터링된다. 기존 토큰 수준 라우팅의 한계를 문서 컨텍스트로 돌파하려는 시도다.
⚠️ 출처 한계 고지: 현재 공개된 1차 출처는 AI2가 공유한 이미지(Reddit 링크)이며, 공식 arXiv 논문 및 기술 블로그는 아직 확인되지 않았습니다. 이 포스트의 기술 설명 중 일부는 공개 이미지에서 추론한 내용을 포함하며, 해당 부분은 별도 표기합니다. AI2 공식 발표(allenai.org)를 통해 1차 검증을 권장합니다.
배경: 기존 MoE 라우팅의 구조적 문제
Mixture of Experts 아키텍처는 전체 파라미터 중 일부(활성 파라미터)만 추론에 사용하는 조건부 연산(conditional computation) 패러다임이다. Mistral의 Mixtral, Google의 Switch Transformer 등 주요 MoE 모델들은 공통적으로 토큰 수준 라우팅(token-level routing)을 채택한다. 각 토큰이 게이팅 네트워크(gating network)를 통해 상위 K개의 전문가로 독립적으로 분기되는 방식이다.
그러나 이 방식에는 구조적 약점이 있다.
- 컨텍스트 단절: 동일 문서 내 토큰들이 서로 다른 전문가로 분산되어, 전문가가 일관된 도메인 지식을 축적하기 어렵다.
- 표면 패턴 과적합: 게이팅 네트워크가 토큰의 어휘적 특성(surface pattern)에 과도하게 반응하고, 의미론적 도메인을 학습하지 못하는 경향이 보고된다.
- 부하 불균형: 특정 전문가로 트래픽이 집중되는 expert collapse 현상이 발생한다.
AI2(Allen Institute for AI)의 EMO는 이 문제를 라우팅 단위를 문서로 상향하는 방식으로 접근한다.
핵심 메커니즘: Document-Level Routing
라우팅 단위의 전환
EMO의 핵심 아이디어는 단순하지만 파급력이 크다. 라우팅 결정을 토큰마다 내리는 것이 아니라, 문서 단위로 한 번 내린다. 해당 문서에 속한 모든 토큰은 동일한 전문가 집합을 통과한다.
[기존 Token-Level Routing]
Token_1 → Router → Expert_3
Token_2 → Router → Expert_7
Token_3 → Router → Expert_3
...
[EMO Document-Level Routing]
Document (Token_1 ~ Token_N) → Router → Expert_2 (고정)
→ Token_1, Token_2, ... Token_N 모두 Expert_2 통과
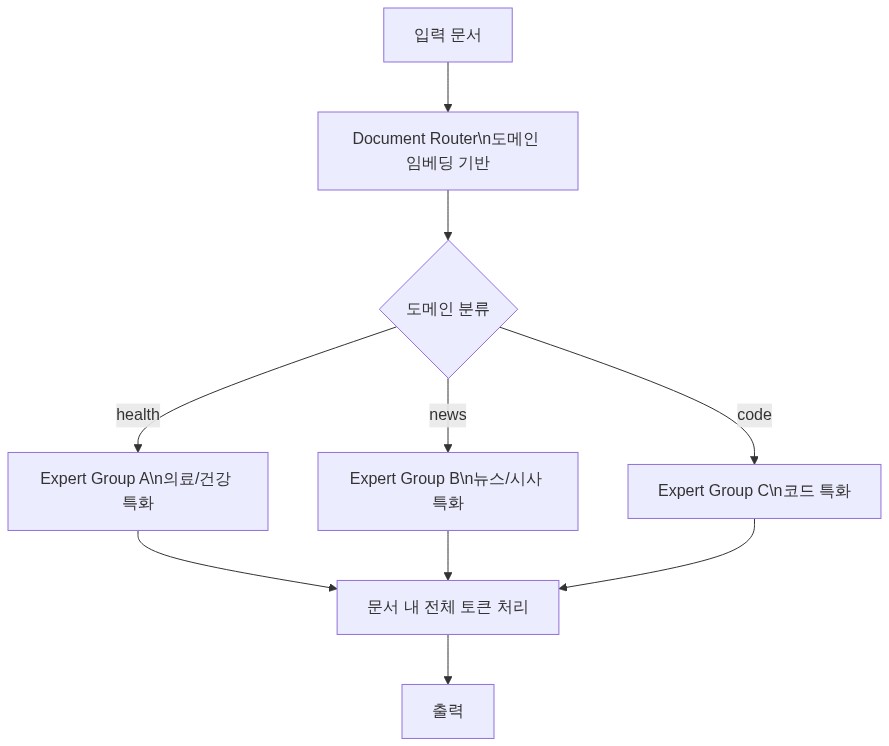
문서 라우터의 구현 구조 (추론 기반)
공개된 정보만으로 구현 세부사항 전체를 확인할 수는 없으나, 문서 수준 라우팅을 구현하는 일반적인 방식과 공개 이미지에서 확인 가능한 정보를 바탕으로 구조를 설명한다. 아래 내용 중 ⚠️ 표기 항목은 원문에서 직접 확인되지 않은 추론이므로 공식 논문 발표 후 검증이 필요하다.
문서 임베딩 생성 ⚠️
토큰 수준 라우터가 각 토큰의 히든 스테이트 $h_t$를 직접 입력으로 받는 것과 달리, 문서 수준 라우터는 문서 전체를 대표하는 단일 벡터를 먼저 생성해야 한다. 가장 단순한 구현은 문서의 첫 $N$개 토큰 히든 스테이트의 평균(mean pooling)을 사용하는 것이다.
$$\mathbf{d} = \frac{1}{N} \sum_{t=1}^{N} h_t$$
라우터 네트워크 ⚠️
생성된 문서 임베딩 $\mathbf{d}$는 선형 프로젝션과 softmax를 거쳐 전문가 선택 확률로 변환된다.
$$\mathbf{g} = \text{softmax}(\mathbf{W}_r \cdot \mathbf{d} + \mathbf{b}_r)$$
여기서 $\mathbf{W}r \in \mathbb{R}^{E \times d{model}}$, $E$는 전문가 수, $d_{model}$은 모델 히든 차원이다. 상위 $K$개 전문가를 선택하는 Top-K 게이팅이 적용된다.
부하 균형 손실 ⚠️
전문가 간 부하 불균형을 방지하기 위해 보조 손실(auxiliary loss)이 추가될 가능성이 높다. Switch Transformer 계열에서 일반적으로 사용되는 형태는 다음과 같다.
$$\mathcal{L}{\text{aux}} = \alpha \cdot E \cdot \sum{e=1}^{E} f_e \cdot P_e$$
여기서 $f_e$는 전문가 $e$로 라우팅된 문서 비율, $P_e$는 라우터가 전문가 $e$에 할당한 평균 확률, $\alpha$는 보조 손실 가중치다. 단, 문서 단위 라우팅에서는 토큰 단위 대비 배치 내 문서 수가 적어 이 손실의 분산이 커질 수 있다는 점이 구현상 도전 과제다.
전문가의 도메인 클러스터링
문서 단위 라우팅의 결과, 각 전문가는 자연스럽게 특정 도메인의 데이터를 반복적으로 학습하게 된다. AI2가 공개한 이미지 분석에 따르면, 전문가들이 health, news 등 의미론적으로 일관된 도메인을 중심으로 클러스터링되는 현상이 관찰된다. 이는 라우팅을 명시적으로 도메인 레이블로 지도학습한 것이 아니라, 표면 패턴이 아닌 도메인 수준의 신호를 학습한 결과로 해석된다. 단, 이 클러스터링이 완전히 자발적으로 발생하는지, 아니면 사전 도메인 정보가 일부 활용되는지는 공식 논문 발표 전까지 확인하기 어렵다.
파라미터 구성
| 항목 | 수치 | 비고 |
|---|---|---|
| 활성 파라미터 | 1B | 원문 확인 |
| 전체 파라미터 | 14B | 원문 확인 |
| 학습 토큰 | 1T | 원문 확인 |
| 활성 비율 | 미확인 | 원문에 명시 없음 |
활성 파라미터 1B로 14B 전체 파라미터를 운용하는 구조는, 추론 비용을 1B 밀집 모델 수준으로 유지하면서 14B 수준의 지식 용량을 확보하는 전형적인 MoE 트레이드오프다.
한국 개발 환경과의 연결: 도메인 특화 서비스에서의 시사점
카카오, 네이버, 토스 같은 국내 플랫폼들은 단일 모델로 다양한 도메인을 처리해야 하는 상황에 놓여 있다. 예를 들어 네이버는 뉴스, 쇼핑, 지식iN, 의료 정보를 하나의 LLM 인프라에서 서빙해야 하는 수요가 있다.
기존 토큰 수준 MoE에서는 동일 문서 내 토큰들이 여러 전문가로 분산되어 KV 캐시 재사용률이 낮아지고, 배치 처리 효율이 저하된다. Document-level routing은 동일 문서의 토큰들이 동일 전문가로 집중되므로, KV 캐시 지역성(locality)이 높아져 서빙 인프라 최적화에 유리하다. 도메인별 트래픽 패턴이 명확한 서비스(의료 챗봇, 금융 Q&A 등)에서는 특정 전문가 그룹만 hot-path에 올려두는 전략도 가능해진다.
실제 적용 시나리오 (공식 모델 공개 이후 기준)
EMO가 Hugging Face Hub에 공개될 경우, 아래와 같은 방식으로 로드 및 추론이 가능할 것으로 예상된다. 현재 모델은 공개되지 않았으므로 아래 코드는 예시이며, 실제 공개 시 API가 달라질 수 있다.
# 모델 다운로드 (공개 후 사용 가능)
pip install huggingface_hub transformers
huggingface-cli download allenai/EMO-14B --local-dir ./emo-14b
# 추론 예시 (공개 후 검증 필요)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "allenai/EMO-14B" # 공개 후 실제 경로로 교체
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto", # 다중 GPU 자동 분산
)
# 문서 단위 입력 (도메인 신호가 충분한 길이 권장)
prompt = "당뇨병 환자의 식이 관리에서 혈당 지수(GI)를 고려한 식단 구성 방법은?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
vLLM을 활용한 서빙 (⚠️ MoE 지원 여부 공개 후 확인 필요)
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model allenai/EMO-14B \
--tensor-parallel-size 2 \ # A100 40GB × 2 기준
--dtype bfloat16 \
--max-model-len 4096
하드웨어 요구사항 (추정)
| 구성 | 사양 | 비고 |
|---|---|---|
| 최소 추론 (활성 1B 기준) | GPU 메모리 약 4–6GB | bfloat16, 활성 파라미터만 고려 |
| 전체 파라미터 로드 | GPU 메모리 약 28GB | bfloat16, 14B × 2bytes |
| 권장 서빙 구성 | A100 40GB × 1 또는 A10G × 2 | ⚠️ 추정치, 공식 확인 필요 |
참고: MoE 모델은 전체 파라미터를 메모리에 올려야 하지만 추론 시 활성 파라미터만 연산에 사용한다. 따라서 메모리 요구사항은 14B 기준으로, 연산 비용은 1B 기준으로 계획하는 것이 일반적이다.
성능 비교: 공개된 정보의 한계
현재 공개된 소스(Reddit 이미지)에서는 Mixtral-8x7B, OLMoE 등 기존 MoE 모델 대비 구체적인 벤치마크 수치(처리량 tokens/sec, 지연시간 ms, MMLU/HellaSwag 점수)가 확인되지 않는다. 아래 표는 유사 규모 MoE 모델의 공개된 수치를 참고용으로 제시한다.
| 모델 | 활성 파라미터 | 전체 파라미터 | MMLU | 처리량(A100) |
|---|---|---|---|---|
| Mixtral-8x7B | 13B | 47B | 70.6 | ~2,000 tok/s |
| OLMoE-1B-7B | 1B | 7B | 52.0 | ~4,500 tok/s |
| EMO | 1B | 14B | 미공개 | 미공개 |
EMO의 실제 벤치마크는 공식 논문 발표 후 이 표를 업데이트할 예정이다. OLMoE(1B/7B)가 가장 직접적인 비교 대상이 될 것으로 보이며, 동일한 활성 파라미터 규모에서 document-level routing이 성능 향상을 가져오는지가 핵심 검증 포인트다.
한계 및 열린 질문
EMO의 접근 방식에는 몇 가지 검토가 필요한 지점이 있다.
1. 짧은 텍스트에서의 라우팅 정확도
문서 수준 라우팅은 문서가 충분한 길이를 가질 때 도메인 신호가 명확하다. 단문 쿼리나 혼합 도메인 문서(예: 의료+법률이 혼재된 계약서)에서 라우팅 품질이 어떻게 유지되는지는 공개된 정보만으로는 확인하기 어렵다.
2. 라우팅 오버헤드
토큰 수준 라우팅은 각 레이어에서 경량 게이팅 연산으로 수행되지만, 문서 수준 라우팅은 문서 전체를 선처리(pre-encode)해야 할 가능성이 있다. 이 오버헤드가 스트리밍 추론 환경에서 어떻게 처리되는지 불명확하다.
3. 전문가 수와 도메인 커버리지
14B 전체 파라미터에서 전문가 수가 몇 개인지, 각 전문가가 커버하는 도메인 수가 몇 개인지 현재 공개된 정보에서 확인되지 않는다. 전문가 수가 적으면 도메인 커버리지가 조악해지고, 많으면 부하 불균형 문제가 재현될 수 있다.
결론
EMO의 document-level routing은 MoE 아키텍처에서 오랫동안 암묵적으로 수용되어 온 “토큰이 라우팅의 기본 단위”라는 가정을 정면으로 재검토한다. 전문가가 도메인을 학습하도록 유도하는 가장 직접적인 방법은, 도메인이 일관된 단위(문서)로 라우팅하는 것이라는 논리는 직관적이다. 활성 파라미터 1B라는 경량 규모에서 이 메커니즘이 어느 수준의 성능을 달성하는지, 그리고 도메인 클러스터링이 실제로 다운스트림 태스크 성능으로 이어지는지가 이 모델의 실질적 가치를 판단하는 기준이 될 것이다.
전문화된 서비스 도메인을 다루는 국내 AI 팀이라면, EMO의 공식 논문과 평가 결과를 주시할 필요가 있다.
출처:
– AI2 EMO 공개 이미지 (Reddit) — 현재 확인 가능한 1차 소스
– Allen Institute for AI 공식 사이트 — 공식 논문/블로그 발표 예정
– OLMoE 논문 (arXiv:2409.02060) — 동일 연구팀의 선행 MoE 연구, 비교 참고용
– Switch Transformer (Fedus et al., 2021) — 부하 균형 손실 함수 참고