
TL;DR
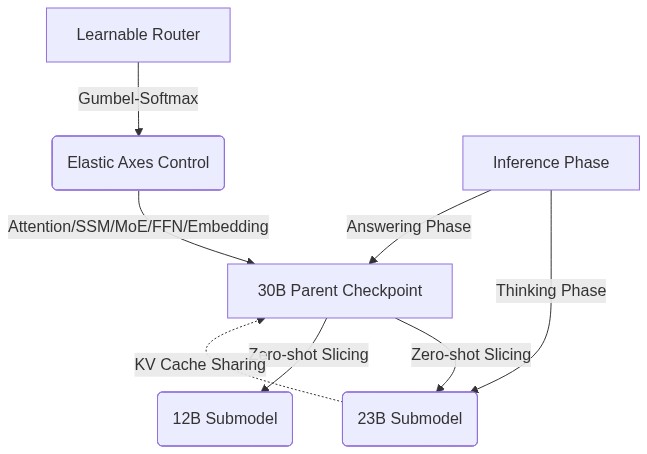
NVIDIA가 단일 체크포인트에서 30B, 23B, 12B 모델을 제로샷으로 추출하는 Star Elastic 구조를 공개했다. Gumbel-Softmax 기반 라우터가 어탠션 헤드, MoE 전문가 등 탄력적 축을 제어하며, 사고와 답변 단계에 따라 모델 용량을 동적 할당하는 것이 핵심이다. 이는 단일 체크포인트 기반의 스펙트럼 추론 제어를 가능케 한다.
배경
대규모 언어 모델(LLM) 배포의 고질적 문제는 태스크별 연산량 요구치의 차이다. 간단한 요약엔 소형 모델이, 복잡한 추론엔 대형 모델이 필요하므로 서비스 사례마다 개별 체크포인트를 유지해야 한다. 이는 스토리지 및 VRAM 관리 비용을 기하급수적으로 증가시킨다. 확장 가능한 비디오 코딩(Scalable Video Coding)이 하나의 비트스트림에서 UHD, HD, SD 화질을 추출하듯, LLM 또한 단일 체크포인트에서 다양한 파라미터 예산의 모델을 즉각적으로 슬라이싱할 수 있는 구조가 요구되었다. NVIDIA의 Star Elastic은 바로 이 지점에서 러시안 인형처럼 여러 크기의 모델을 중첩하는 혁신을 제시한다.
핵심 메커니즘
Star Elastic은 Nemotron Nano v3에 사후 훈련(post-training) 방법을 적용하여 30B 부모 모델 내부에 23B, 12B 서브모델을 중첩(Nested)하는 방식을 취한다. 이를 제로샷 슬라이싱(Zero-shot Slicing)이라 부르며, BF16, FP8, NVFP4 정밀도를 모두 단일 체크포인트에서 지원한다. 기술적 핵심은 다음 세 가지다.
- 탄력적 축 (Elastic Axes): 어탠션 헤드, Mamba SSM 헤드, MoE 전문가, FFN 채널, 임베딩 차원 등 모델의 거의 모든 구성 요소를 독립적으로 조정 가능한 축으로 취급한다.
- 중요도 기반 순위 및 라우터: 사후 훈련 시작 전 각 구성 요소의 중요도를 L1 노름 기반 프루닝 및 그래디언트 민감도 등의 메트릭으로 사전 계산(Importance-based ranking)하여 순위를 매긴다. 학습 가능한 라우터는 Gumbel-Softmax를 통해 목표 파라미터 예산에 맞춰 최적의 중첩 구성을 매핑한다.
- KV 캐시 공유 및 단계별 할당: 중첩된 모델 간 KV 캐시를 공유하여 속도를 슬라이딩 스케일처럼 조절한다. 특히 ‘탄력적 예산 제어(Elastic budget control)’를 통해 사고(Thinking) 단계에서는 23B 서브모델로 연산량을 절감하고, 최종 답변(Answering) 단계에서는 30B 부모 모델을 투입하는 전략이 가능하다.
코드/수식
라우터의 핵심은 연속적인 파라미터 공간에서 이산적인 모델 구성을 미분 가능하게 선택하는 것이다. Gumbel-Softmax를 통해 라우터는 탄력적 축에 대한 마스킹을 학습한다.
$$
\pi_i = \text{Router}(x), \quad p_i = \frac{\exp((\log \pi_i + g_i) / \tau)}{\sum_j \exp((\log \pi_j + g_j) / \tau)}
$$
여기서 $g_i$는 Gumbel 노이즈, $\tau$는 온도 파라미터다. 이를 통해 목표 예산에 맞춰 어탠션 헤드나 MoE 전문가를 드롭아웃하는 구성을 end-to-end로 최적화한다. 구체적으로 라우터가 출력하는 확률 $p_i$를 바탕으로 각 탄력적 축(헤드, 전문가 등)에 이진 마스크를 생성하고, 이 마스크를 해당 축의 가중치에 곱하여 불필요한 구성 요소를 미분 가능하게 제거(pruning)함으로써 수식과 실제 마스킹이 연결된다.
단계별 모델 할당은 다음과 같은 의사코드로 구현될 수 있다.
from transformers import AutoModelForCausalLM, AutoTokenizer
def elastic_budget_control(input_ids, thinking_budget="23B", answering_budget="30B"):
# 단일 체크포인트에서 모델 로드
model = AutoModelForCausalLM.from_pretrained('nvidia/star-elastic-30b', device_map="auto")
tokenizer = AutoTokenizer.from_pretrained('nvidia/star-elastic-30b')
# 1. Thinking Phase: 23B 서브모델로 빠르게 사고 (KV 캐시 생성)
thinking_output, kv_cache = model.generate(
input_ids,
target_params=thinking_budget, # 라우터가 23B 구성으로 어탠션/FFN 슬라이싱
use_cache=True
)
# 2. Answering Phase: 30B 부모 모델로 정밀한 답변 생성 (KV 캐시 공유)
answering_output = model.generate(
thinking_output,
target_params=answering_budget, # 라우터가 30B 구성으로 복원
past_key_values=kv_cache # 이전 단계 KV 캐시 재사용
)
return answering_output
[하드웨어별 권장 설정 및 VRAM 요구량]
| 모델 크기 (활성 파라미터) | 정밀도 | 최소 VRAM 요구량 | 권장 GPU |
|—|—|—|—|
| 30B | BF16 | ~64GB | A100 80GB |
| 23B | BF16 | ~48GB | A100 80GB / RTX 6000 Ada |
| 12B | BF16 | ~26GB | RTX 4090 24GB* / A10G |
* 12B BF16 기준 26GB 필요로 RTX 4090(24GB) 환경에서는 FP8/NVFP4 양자화 필요
이러한 동적 할당은 한국의 서비스 환경, 예컨대 네이버의 HyperCLOVA X나 카카오의 Kanana 서비스 인프라에 즉각적인 최적화 포인트를 제공한다. 검색 요약이나 내부 도구 호출 시에는 12B/23B 모델로 초저지연 응답을 제공하고, 복잡한 논리 추론이 필요한 고객 대응 시에는 30B 모델로 동적 전환하여 GPU 자원을 효율적으로 운용하는 MLOps 파이프라인 구축이 단일 체크포인트로 가능해진다.
한계
본 정보는 공식 기술 블로그나 논문이 아닌 Reddit 커뮤니티 게시글에 기반하므로, 1차 출처의 기술적 정확성을 완전히 담보하지 않는다. 12B 모델의 ‘7000 tokens/s’ 추론 속도는 작성자가 단일 RTX 4090 및 Batch Size 1 환경을 전제로 도출한 해석적 수치일 뿐 공식 검증되지 않았다. 또한 ‘사고 단계 23B, 답변 단계 30B’ 전략의 실제 벤치마크 성능 비교 데이터, 단계 전환 시 발생하는 오버헤드, 30B 부모 모델의 실제 VRAM 요구량 등 정량적 데이터가 전무하다. Dense와 MoE의 하이브리드 중첩 구조가 라우팅 축 간의 간섭이나 그래디언트 소실 없이 어떻게 안정적으로 훈련되는지에 대한 기술적 검증도 후속 논문을 통해 확인해야 한다.
결론
Star Elastic은 모델 배포의 단위를 ‘고정된 모델 크기’에서 ‘유연한 파라미터 예산’으로 전환하는 패러다임 시프트를 제시한다. 30B 모델로 아이디어를 탐색하고, 12B 모델로 초고속 검증을 수행한 뒤 다시 30B로 평가하는 유기적인 추론 워크플로우는 로컬 환경은 물론 엣지 디바이스에서의 효율적 연산 분배를 설계할 단초를 제공한다. 정식 논문과 정량적 벤치마크 공개가 남은 과제이나, 단일 체크포인트 다중 모델 추론의 방향성을 명확히 제시했다는 점에서 그 파급력이 상당하다.