TL;DR
LLM 모델 및 API 호스팅 제공자 비교 시, ArtificialAnalysis.ai는 품질·가격·기술 성능(처리량/지연시간)을 단일 플랫폼에서 교차 검증할 수 있는 현재 가장 체계적인 공개 벤치마크 소스다. 3시간 간격으로 실제 API 요청을 전송해 측정하므로 정적 리포트 대비 시계열 신뢰도가 높다. 단, “objective”라는 표현은 마케팅 언어임을 감안하고 방법론 한계를 직접 검토한 후 의사결정에 활용해야 한다.
비교 대상 소개: ArtificialAnalysis.ai가 다루는 세 가지 데이터 축
LLM 선택 과정에서 개발자가 직면하는 문제는 단순히 “어느 모델이 더 똑똑한가”가 아니다. 같은 모델이라도 어느 API 제공자를 통해 호출하느냐에 따라 처리량(throughput), 지연시간(latency), 비용이 크게 달라진다. ArtificialAnalysis.ai는 이 세 축을 통합 비교하는 것을 핵심 가치로 삼는다.
플랫폼이 통합하는 데이터는 크게 세 종류다.
- 품질 벤치마크: MMLU, HumanEval 등 기존 공개 벤치마크 결과를 집계
- 가격 정보: 모델별·제공자별 토큰당 비용
- 자체 기술 벤치마킹: 처리량과 지연시간을 직접 측정한 데이터
세 번째 항목이 이 플랫폼의 차별점이다. 공개 벤치마크는 시점이 고정된 스냅샷인 반면, ArtificialAnalysis.ai는 3시간마다 실제 API 요청을 전송해 측정값을 갱신한다.
기준별 비교: 측정 항목과 방법론
아래 표는 플랫폼이 제공하는 세 데이터 축의 특성을 정리한 것이다. 원문에 명시되지 않은 수치는 포함하지 않았다.
| 데이터 축 | 측정 대상 | 측정 방법 | 비고 |
|---|---|---|---|
| 품질 벤치마크 | 모델 정확도·추론 능력 | 기존 공개 벤치마크 집계 | 외부 출처 통합 |
| 가격 정보 | 토큰당 비용 | 제공자 공시 가격 수집 | 제공자별 비교 가능 |
| 기술 성능 | 처리량(throughput), 지연시간(latency) | 3시간 간격 실제 API 요청 전송 | 자체 측정, 시계열 추적 |
기술 벤치마킹 방법론의 실제와 한계
처리량과 지연시간은 LLM API 성능 평가에서 서로 다른 의미를 갖는다.
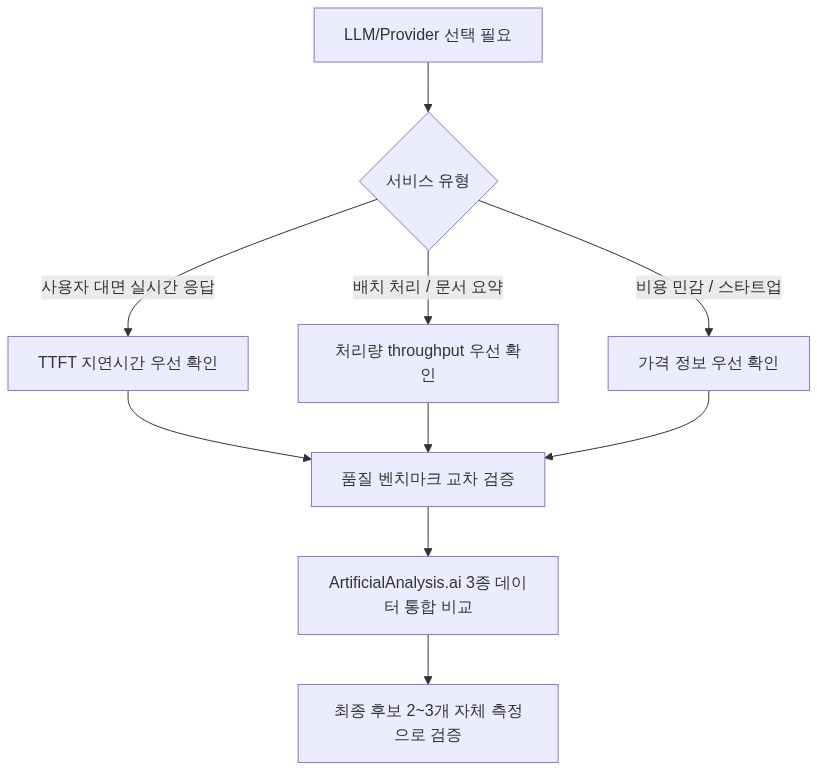
- 처리량(throughput): 단위 시간당 생성 토큰 수(tokens/sec). 배치 처리나 대용량 문서 요약처럼 총 소요 시간이 중요한 워크로드에 직접적인 영향을 준다.
- 지연시간(latency): 요청 전송 후 첫 토큰이 도달하기까지의 시간(TTFT, Time To First Token). 실시간 스트리밍 응답이 필요한 사용자 대면 서비스에서 체감 품질을 결정한다.
ArtificialAnalysis.ai는 이 두 지표를 실제 API 호출을 통해 측정한다고 밝히고 있으나, 구체적인 측정 방식은 공개되지 않는다. 이 점이 단순한 투명성 문제를 넘어 실질적인 해석 오류로 이어질 수 있는 이유는 다음과 같다.
동시 요청 수(concurrency)의 영향: LLM 추론 서버는 요청을 배치로 묶어 GPU를 병렬 활용한다. 단일 요청(concurrency=1) 환경에서는 GPU 활용률이 낮아 처리량이 과소 측정될 수 있고, 반대로 동시 요청이 많으면 큐 대기 시간이 지연시간에 합산된다. 동일 모델·동일 제공자라도 concurrency 설정에 따라 측정된 처리량이 수 배 이상 달라지는 것은 흔한 일이다.
배치 크기와 프롬프트 길이의 영향: 서버 측 배치 크기(batch size)가 1일 때와 32일 때 처리량은 이론상 최대 10배 이상 차이가 날 수 있다. 프롬프트 길이 역시 KV 캐시 메모리 점유에 영향을 주어 처리량을 변화시킨다. 짧은 프롬프트로 측정한 처리량 수치를 장문 문서 요약 워크로드에 그대로 적용하면 실제 성능과 크게 괴리될 수 있다.
모델 양자화 여부: 동일한 모델명이라도 FP16 전체 정밀도로 서빙하는 제공자와 INT4/INT8 양자화 버전을 서빙하는 제공자 간에는 처리량과 품질 모두 차이가 생긴다. 플랫폼이 이를 구분해 표시하는지는 확인이 필요하다.
플랫폼 자체도 “All feedback is welcome and happy to discuss methodology”라고 명시하고 있어, 방법론이 고정된 완성형이 아님을 시사한다. 따라서 플랫폼 수치는 상대적 순위 파악에는 유용하지만, 자신의 워크로드 조건과 다를 수 있음을 전제하고 최종 후보는 직접 측정으로 검증해야 한다.
시나리오별 선택 가이드
어떤 데이터 축을 우선할 것인가
한국 개발 환경에서의 활용 포인트
국내 서비스 개발 환경에서 ArtificialAnalysis.ai를 활용할 때 고려해야 할 구조적 한계가 있다.
국내 주요 LLM 제공자의 포함 여부: ArtificialAnalysis.ai는 현재 OpenAI, Anthropic, Google, Meta 등 글로벌 제공자 중심으로 구성되어 있다. Naver HyperCLOVA X, Kakao의 한국어 특화 모델 등 국내 제공자는 플랫폼에 포함되어 있지 않거나 커버리지가 제한적이다. 즉, 이 플랫폼만으로는 국내 제공자와 글로벌 제공자를 동일 기준으로 비교할 수 없다.
한국어 성능이 빠진 비교의 맹점: 플랫폼이 집계하는 MMLU, HumanEval 등 벤치마크는 대부분 영어 기반이다. 실제 국내 서비스 개발자가 직면하는 선택 딜레마는 다음과 같은 형태다.
| 비교 시나리오 | 글로벌 벤치마크 기준 | 실제 한국어 서비스 기준 |
|---|---|---|
| GPT-4o vs Claude 3.5 Sonnet | 처리량·비용 차이 미미 | 한국어 뉘앙스·존댓말 처리 품질 차이 존재 |
| GPT-4o vs HyperCLOVA X | ArtificialAnalysis.ai 비교 불가 | 한국어 성능·데이터 주권·가격 모두 다름 |
| 저비용 오픈소스(Llama 3) vs 상용 API | 처리량 유리할 수 있음 | 자체 인프라 운영 비용·한국어 파인튜닝 필요 |
네트워크 지연과 측정 서버 위치: 플랫폼의 기술 벤치마킹은 측정 서버의 물리적 위치에 따라 네트워크 왕복 시간이 결과에 포함된다. 서울 리전 기반 서비스라면 표시된 지연시간 수치를 그대로 신뢰하기보다, 동일 프롬프트를 국내 인프라에서 직접 측정한 값과 비교하는 것이 필수다.
데이터 주권 항목의 부재: 국내 기업들이 LLM API를 선택할 때는 데이터 주권(data residency) 및 개인정보보호법 준수 여부가 기술 성능 못지않게 중요한 변수다. ArtificialAnalysis.ai는 현재 이 항목을 별도 축으로 제공하지 않으므로, 각 제공자의 데이터 처리 정책을 별도로 검토해야 한다.
결론
ArtificialAnalysis.ai는 분산된 LLM 벤치마크 정보를 품질·가격·기술 성능 세 축으로 통합한다는 점에서 실용적인 비교 도구다. 3시간 간격의 실측 데이터는 정적 리포트보다 현실을 더 잘 반영하지만, 측정 방법론의 세부 파라미터가 공개되지 않은 점은 한계다. “objective benchmarks”라는 표현을 액면 그대로 수용하기보다, 최종
결론
ArtificialAnalysis.ai는 분산된 LLM 벤치마크 정보를 품질·가격·기술 성능 세 축으로 통합한다는 점에서 실용적인 비교 도구다. 3시간 간격의 실측 데이터는 정적 리포트보다 현실을 더 잘 반영하지만, 측정 방법론의 세부 파라미터가 공개되지 않은 점은 한계다. “objective benchmarks”라는 표현을 액면 그대로 수용하기보다, 최종 선택은 자신의 워크로드와 유사한 조건에서 직접 측정한 결과로 검증해야 한다. 특히 국내 개발 환경에서는 한국어 성능, 데이터 주권, 네트워크 지연이라는 세 가지 변수가 추가되므로, 이 플랫폼을 글로벌 제공자 간 1차 필터링 도구로 활용하고 최종 결정은 자체 평가를 병행하는 전략이 현실적이다. 결국 LLM API 선택은 단일 벤치마크 점수가 아닌, 서비스 목표와 제약 조건을 종합적으로 저울질하는 의사결정 과정임을 기억해야 한다.