
TL;DR
Hacker News AI 콘텐츠 편중 문제는 플랫폼 분리보다 알고리즘 구조의 문제로 이해해야 한다. HN의 업보트 메커니즘은 특정 시기 특정 주제가 집중되면 자기강화 효과를 일으킨다. 한국 백엔드·ML 개발자라면 HN을 ‘발견의 채널’로 쓸지 ‘검증의 채널’로 쓸지 먼저 정의하는 것이 핵심이다.
비교 대상 소개: 무엇을 선택하는가
최근 Hacker News 커뮤니티에서 흥미로운 질문이 제기됐다. “AI/LLM 콘텐츠와 그 외 콘텐츠로 HN을 분리할 때가 됐는가?” (원문)
원문 작성자는 정량 데이터 없이 개인적 체감을 기반으로 문제를 제기했다. 그러나 이 질문은 단순한 콘텐츠 취향 문제가 아니다. 기술 커뮤니티의 알고리즘 설계, 집단 관심의 쏠림 현상, 그리고 정보 소비 전략에 관한 구조적 질문이다.
이 포스트에서는 다음 두 입장을 비교 분석한다.
- 입장 A: HN을 AI/LLM 피드와 기타 피드로 분리(Fork)해야 한다
- 입장 B: 분리 없이 현행 단일 피드를 유지하되, 개인의 소비 전략을 조정해야 한다
HN 알고리즘은 왜 특정 주제를 증폭시키는가
HN 랭킹 공식은 초기에 부분적으로 알려진 형태가 있었다. 커뮤니티에서 역공학(reverse engineering)을 통해 추정된 근사 공식은 다음과 같다.
Score ≈ (Upvotes - 1)^0.8 / (Age_in_hours + 2)^1.8
그러나 이 공식에는 중요한 단서가 붙는다. HN 운영진(Y Combinator)은 현행 알고리즘의 세부 파라미터를 공식적으로 공개하지 않으며, 특히 2023년 이후에는 스팸 대응 및 품질 관리 목적으로 추가적인 조정 요소가 적용되고 있다고 알려져 있다. 위 공식은 현행 알고리즘의 정확한 반영이 아니라, 커뮤니티 분석을 통해 도출된 구조적 근사값으로 이해해야 한다.
공식의 정확한 수치보다 중요한 것은 초기 업보트 속도라는 핵심 원리다. 게시 직후 빠르게 업보트를 받은 글은 Front Page에 노출되고, 노출이 다시 업보트를 유도하는 자기강화(self-reinforcing) 루프가 형성된다.
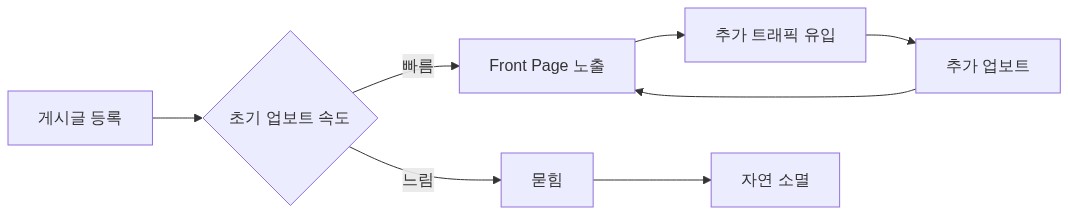
이 구조에서 AI/LLM 콘텐츠가 유리한 이유는 커뮤니티 구성과 직결된다. HN 사용자 구성의 정확한 통계는 공개되지 않지만, HN 자체 스레드의 댓글 패턴과 제출 글의 주제 분포를 보면 AI 스타트업 창업자, ML 엔지니어, VC 관계자의 참여 비중이 체감상 높아졌다는 의견이 다수 제기된다. 이들이 AI 관련 글에 초기 업보트를 집중하면, 알고리즘은 그 신호를 증폭한다. 이는 HN 운영진의 의도가 아니라 업보트 기반 알고리즘의 구조적 결과다.
즉, “AI 콘텐츠가 많다”는 체감은 콘텐츠 자체의 절대량 문제가 아니라, 커뮤니티 구성 변화 → 업보트 패턴 변화 → 알고리즘 증폭의 연쇄 결과일 가능성이 높다. 다만 이 연쇄를 정량적으로 검증한 독립 연구는 현재까지 충분하지 않으며, 체감 기반 가설로 다루는 것이 정확하다.
기준별 비교: Fork vs. 단일 피드 유지
| 기준 | Fork (분리) | 단일 피드 유지 |
|---|---|---|
| 콘텐츠 다양성 | 비AI 주제 발견 용이 | AI 관심 없는 독자에게 노이즈 증가 |
| 커뮤니티 응집력 | 담론 분산, 교차 토론 감소 | 이질적 주제 간 우연한 연결 유지 |
| 알고리즘 복잡도 | 카테고리별 별도 랭킹 필요 | 현행 단일 공식 유지 가능 |
| 운영 비용 | 모더레이션 이중화 | 현행 구조 유지 |
| 선례 | Reddit의 서브레딧 분화 → 에코챔버 심화(단, 복합 요인 존재) | HN 창립 철학(폭넓은 지적 호기심) 유지 |
| 개인화 가능성 | 구조적 분리로 해결 | 개인 필터링 전략으로 대응 가능 |
Reddit의 사례는 참고할 만하지만, 인과관계를 단순화하지 않는 것이 중요하다. 서브레딧 분화 자체가 에코챔버를 만들었다기보다는, 2018년 이후 Reddit이 도입한 추천 알고리즘 강화, 정치적 양극화, 광고 수익 중심의 콘텐츠 정책 변화 등 복합 요인이 에코챔버를 심화시켰다. 서브레딧 분화는 그 구조적 조건 중 하나였을 뿐이다. HN Fork를 반대하는 근거로 Reddit 사례를 쓸 수는 있지만, “분리하면 에코챔버가 된다”는 단선적 인과 주장은 과도하다.
그럼에도 HN이 지금까지 단일 피드를 유지한 것은 이질적 주제 간 우연한 연결, 즉 세렌디피티를 설계 원칙으로 삼았기 때문이라는 점은 유효하다.
시나리오별 선택 가이드
한국 개발자 관점에서의 비용-편익 분석
카카오, 네이버, 토스 같은 국내 테크 기업의 백엔드·ML 엔지니어가 HN을 사용하는 맥락은 크게 두 가지다.
시나리오 1: 기술 트렌드 조기 감지 목적
– AI/LLM 콘텐츠 편중이 오히려 유리하다. LLM 서빙 최적화, RAG 아키텍처, 추론 비용 절감 등의 주제는 현재 국내 AI 팀의 실무 관심사와 직접 연결된다.
– 이 경우 Fork나 필터링은 불필요하다. 현행 HN 피드를 그대로 활용하는 것이 효율적이다.
시나리오 2: 비AI 영역의 기술 발견 목적
– 시스템 프로그래밍, 데이터베이스 내부 구조, 분산 시스템 등 AI 외 기술 심화 학습이 목적이라면, HN의 현행 피드는 노이즈 비용이 증가한다.
– 이때 유효한 전략은 Fork 요청이 아니라 HN 검색 API를 활용한 개인 필터링이다.
import requests
def fetch_hn_stories_excluding_topic(exclude_keywords: list[str], limit: int = 30) -> list[dict]:
"""
HN Algolia API를 활용해 특정 키워드를 제외한 상위 스토리를 반환한다.
공식 문서: https://hn.algolia.com/api
주의: Algolia HN API의 numericFilters는 'points', 'num_comments',
'created_at_i' 필드를 지원한다. 'points>50' 형식은 공식 문서 기준
'points>50'으로 작성하며, 실제 동작은 API 버전에 따라 다를 수 있다.
최신 파라미터 명세는 공식 문서(https://hn.algolia.com/api)에서 확인할 것.
알려진 제약: 키워드 제외(NOT 연산)는 Algolia 표준 쿼리 문법을 따르나,
HN 전용 엔드포인트에서의 동작이 일반 Algolia와 다를 수 있으므로
실제 사용 전 응답 결과를 검증하는 것을 권장한다.
"""
base_url = "https://hn.algolia.com/api/v1/search"
# 제외 키워드를 Algolia 쿼리 문법으로 변환
# NOT 연산자는 Algolia 표준 문법이나, HN API에서의 지원 범위를 확인할 것
exclude_query = " ".join(f'NOT "{kw}"' for kw in exclude_keywords)
params = {
"query": exclude_query,
"tags": "story",
"hitsPerPage": limit,
# numericFilters 문법: Algolia 공식 문서 기준 쉼표 구분 문자열
# 참고: https://www.algolia.com/doc/api-reference/api-parameters/numericFilters/
"numericFilters": "points>50"
}
response = requests.get(base_url, params=params)
response.raise_for_status()
hits = response.json().get("hits", [])
return [
{"title": h["title"], "url": h.get("url", ""), "points": h["points"]}
for h in hits
]
# 사용 예시
stories = fetch_hn_stories_excluding_topic(
exclude_keywords=["LLM", "GPT", "AI agent", "ChatGPT"],
limit=20
)
for s in stories:
print(f"[{s['points']}] {s['title']}")
API 사용 시 주의사항: 위 코드는 HN 공식 Algolia API(https://hn.algolia.com/api)를 기반으로 작성되었으나,
numericFilters의points>50필터 및NOT키워드 제외 연산이 HN 전용 엔드포인트에서 의도대로 동작하는지는 실제 호출로 검증이 필요하다. 프로덕션 환경에 적용하기 전에 응답 데이터를 직접 확인하고, 필요시 클라이언트 사이드 필터링을 병행하는 것을 권장한다. Algolia 파라미터 전체 명세는 공식 문서를 참고하라.
토스나 카카오의 플랫폼팀이 내부 기술 뉴스레터를 자동화할 때도 동일한 API를 활용할 수 있다.
결론: Fork는 해결책이 아니다
원문 작성자의 체감은 타당하다. 그러나 그 원인은 HN의 콘텐츠 정책이 아니라, 업보트 알고리즘과 커뮤니티 구성 변화의 상호작용에 있다. Fork는 이 구조적 원인을 해결하지 못한다.
AI/LLM 콘텐츠가 지배적으로 느껴지는 현상은 기술 투자 트렌드와 커뮤니티 인구 구성이 반영된 결과일 가능성이 높다. 이것을 플랫폼 분리로 해결하려는 시도는, Reddit 사례가 보여주듯 분리 자체뿐 아니라 추천 알고리즘 강화·콘텐츠 정책 변화 등 복합 요인이 맞물릴 때 에코챔버 심화라는 부작용을 낳을 수 있다.
한국 백엔드·ML 개발자에게 실용적인 결론은 하나다. HN을 수동적으로 소비하는 채널로 쓸지, 아니면 API를 통해 능동적으로 필터링하는 데이터 소스로 쓸지를 먼저 정의하라. 플랫폼에 분리를 요청하기 전에, 자신의 소비 전략을 먼저 설계하는 것이 더 효율적이다.
출처: Ask HN: Is it time to fork HN into AI/LLM and “Everything else/other?”
HN Algolia API 문서: https://hn.algolia.com/api
Algolia numericFilters 파라미터 명세: https://www.algolia.com/doc/api-reference/api-parameters/numericFilters/