
TL;DR
LLM 추론을 위한 이종 GPU 클러스터(heterogeneous cluster) 설계에서, Blackwell GPU로 프리필을 처리하고 RDMA를 통해 미확인 고메모리 노드(“Studio Mesh”로 표기된 하드웨어)로 KV Cache를 전달해 디코드를 분리하는 아키텍처가 제안되었다. 저자는 이 구성이 서로 다른 GPU 세대·타입을 물리적으로 혼합한 “first heterogeneous cluster”가 될 것이라 주장하나, 이는 저자 본인의 미검증 주장이며 현재 PoC 단계 스크린샷 수준이다. 현재 Tinygrad 드라이버 통합과 RDMA 구성이 미완료 상태로 보인다.
배경: Prefill-Decode 분리는 이미 알려진 개념이지만, 이 설계는 다르다
LLM 추론 파이프라인에서 프리필(prefill)과 디코드(decode)는 연산 특성이 근본적으로 다르다.
- 프리필: 입력 토큰 전체를 한 번에 처리. 연산 집약적(compute-bound), 병렬화 이득이 크다.
- 디코드: 토큰을 하나씩 자기회귀적으로 생성. 메모리 대역폭 집약적(memory-bound), KV Cache 접근이 병목이다.
이 비대칭성을 해소하기 위한 시도는 이미 존재한다. ByteDance의 DistServe(논문)와 Moonshot의 Mooncake는 소프트웨어 수준에서 프리필 인스턴스와 디코드 인스턴스를 분리한다. 그러나 이들은 동일한 GPU 세대 내에서 역할만 나누는 소프트웨어적 분리다.
이번에 제안된 아키텍처는 다르다. Blackwell(B200 계열)과 대용량 메모리 노드라는 서로 다른 하드웨어 타입을 물리적으로 혼합하여 각 단계에 최적화된 하드웨어를 할당한다. 저자가 “first heterogeneous cluster”라고 명시한 것은 이 지점이다. 다만 이 주장의 근거—즉 선행 사례에 대한 체계적 조사—는 원문에서 제시되지 않는다. DistServe/Mooncake와의 차별점도 “소프트웨어 vs 하드웨어 분리”라는 단순 구분에 머물며, 실제 구현 증거 없이 개념 수준에서 제시된 것임을 감안해야 한다.
핵심 메커니즘: 왜 이 분리가 정량적으로 타당한가
Blackwell이 프리필에 적합한 이유
NVIDIA Blackwell(B200)은 HBM3e를 탑재하며 GPU당 192GB HBM, 8TB/s 메모리 대역폭을 제공한다(NVIDIA B200 공식 스펙). 프리필 단계는 전체 시퀀스를 병렬 처리하므로 높은 FLOPs와 대역폭이 모두 요구된다. Blackwell의 FP8 텐서 코어 처리량은 이 단계에 직접적인 이점을 제공한다.
디코드 노드가 적합한 이유: KV Cache 메모리 계산
⚠️ 하드웨어 명칭 주의: 원문 이미지에서 “Studio Mesh”로 표기된 하드웨어는 NVIDIA 공식 제품 라인에 존재하지 않는 명칭이다. 이하에서는 원문 표기를 따르되, 실제 제품 사양이 검증되지 않은 미확인 고메모리 노드임을 전제로 기술한다. 원문에서 언급된 2.3TB RAM, 400+ vCore 수치 역시 원문 이미지에서 추론된 것으로, 독립적으로 검증되지 않았다.
디코드 단계의 핵심 병목은 KV Cache 크기다. Llama-3 70B 모델을 예로 계산하면:
KV Cache 크기 = 2 × num_layers × num_heads × head_dim × seq_len × batch_size × dtype_bytes
Llama-3 70B 기준:
- num_layers = 80
- num_kv_heads = 8 (GQA)
- head_dim = 128
- seq_len = 8,192 (8K context)
- batch_size = 32
- dtype = FP16 (2 bytes)
= 2 × 80 × 8 × 128 × 8192 × 32 × 2
≈ 85.9 GB (단일 배치)
seq_len = 32K, batch_size = 128 시:
≈ 85.9 × 4 × 4 ≈ 1.37 TB
원문에서 언급된 2.3TB RAM이 실제로 탑재된다면, 이 규모의 KV Cache를 호스트 메모리에 수용할 수 있는 수치다. 디코드는 메모리 대역폭 집약적이므로, 고성능 GPU보다 대용량 메모리와 높은 CPU 코어 수(400+ vCore)가 오히려 비용 효율적인 선택이 될 수 있다.
다만 이 비용 효율성 주장은 정량적 비교 없이는 단언하기 어렵다. 예를 들어 H100 SXM 8장(~80GB × 8 = 640GB HBM, 약 $25,000~30,000/월 클라우드 기준)과 미확인 고메모리 노드의 실제 단가·처리량(tokens/sec/dollar)을 비교한 데이터가 원문에는 존재하지 않는다. “비용 효율적”이라는 결론은 현재 가설 수준으로 받아들여야 한다.
RDMA를 통한 KV Cache 전달
프리필 완료 후 생성된 KV Cache를 Blackwell에서 디코드 노드로 전달하는 경로가 RDMA다.
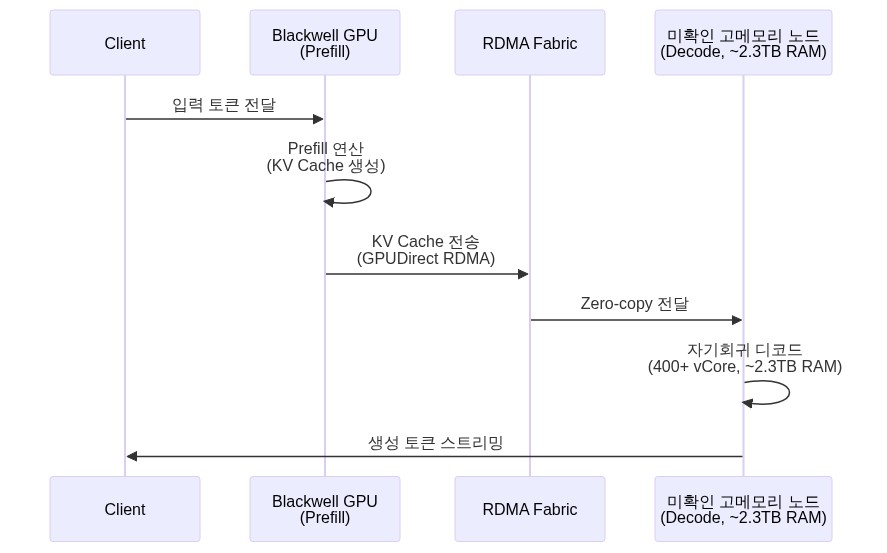
GPUDirect RDMA를 활용하면 GPU 메모리에서 원격 노드 메모리로 CPU를 거치지 않고 직접 전송이 가능하다. 이는 KV Cache 이동 지연을 최소화하는 핵심 경로다.
현재 한계와 미완성 지점
원문에서 추론된 미완성 항목
원문 이미지에서 미완료로 보이는 항목은 다음 두 가지다. 다만 이는 원문에서 명시적으로 열거된 것이 아니라 스크린샷 맥락에서 추론된 것임을 밝힌다.
1. Tinygrad 드라이버 통합
Tinygrad는 경량 ML 프레임워크로, 커스텀 하드웨어 백엔드 지원을 위한 드라이버 레이어가 필요하다. 이종 클러스터에서 Blackwell과 디코드 노드 간 연산 그래프를 조율하려면 Tinygrad가 양쪽 하드웨어를 추상화할 수 있어야 한다.
2. RDMA 드라이버 구성
실제 RDMA 연결 구성은 ibverbs 또는 UCX 레이어에서 이루어진다. Blackwell의 NVLink/PCIe 토폴로지와 디코드 노드 간 RDMA 경로 설정, QP(Queue Pair) 초기화, MR(Memory Region) 등록이 완료되어야 한다.
실제 구현 시 예상되는 추가 난제
개념 증명에서 실제 운영 수준으로 넘어가려면 다음 문제들이 추가로 해결되어야 한다.
① RDMA 전송 지연과 GPU 메모리 전송 트레이드오프
InfiniBand HDR(200Gbps) 기준으로 1.37TB KV Cache를 전송하면 이론상 약 55초가 소요된다. 실제 서비스에서 허용 가능한 TTFT(Time to First Token) 목표와의 간극을 어떻게 메울 것인지가 핵심 과제다. 프리필 완료 직후 KV Cache 전체를 전송하는 방식 대신, 레이어 단위 파이프라인 전송(layer-wise pipelining)이 필요할 수 있으나 이에 대한 설계는 원문에 없다.
② 동적 배치 크기 변동에 따른 메모리 관리
실제 서비스에서 배치 크기와 시퀀스 길이는 요청마다 다르다. KV Cache 크기가 동적으로 변하는 상황에서 2.3TB RAM을 효율적으로 분할·회수하는 메모리 관리 정책(예: PagedAttention 방식의 블록 단위 할당)이 필요하다. 이 부분이 없으면 메모리 단편화로 인해 실효 용량이 크게 줄어든다.
③ 이종 하드웨어 간 장애 격리와 복구
Blackwell 노드와 디코드 노드가 물리적으로 분리된 구조에서, 한쪽 노드 장애 시 진행 중인 디코드 세션의 KV Cache를 어떻게 처리할 것인지 정책이 필요하다. 동일 노드 내 장애보다 복구 경로가 복잡하며, RDMA 연결 재수립 비용도 고려해야 한다.
이 세 가지는 개념 증명(PoC) 수준에서 시스템 통합 수준으로 넘어가는 가장 어려운 공학적 구간이다.
“First Heterogeneous Cluster” 주장의 한계
저자가 이 설계를 “first heterogeneous cluster”라고 명시했으나, 이 주장에는 몇 가지 유보가 필요하다.
- 선행 사례 조사 부재: 원문은 이 주장을 뒷받침하는 선행 사례 검토를 제시하지 않는다. 학계나 산업계에서 이종 GPU 혼합 추론 클러스터 연구가 전무하다는 근거가 없다.
- 구현 증거 없음: 원문은 개념 설계 단계의 스크린샷이며, 실제 동작하는 시스템의 벤치마크나 로그가 아니다.
- “이종성”의 정의 모호: DistServe도 역할 분리라는 의미에서 이종적이다. “하드웨어 타입의 물리적 혼합”을 이종성의 기준으로 삼는다면, 이 정의 자체를 명확히 해야 한다.
결론
이 설계의 핵심 가치는 하드웨어 이종성을 연산 특성의 비대칭성에 맞게 정렬한다는 점이다. 프리필의 compute-bound 특성에는 Blackwell의 고밀도 연산 능력을, 디코드의 memory-bound 특성에는 대용량 RAM을 가진 노드를 배치하는 구조는 방향성 측면에서 합리적이다.
국내 LLM 서비스 관점에서 시사점을 찾는다면, 이 아키텍처가 제기하는 질문은 다음과 같다: “동일 세대 GPU를 균일하게 확장하는 것이 항상 최선인가?” 긴 컨텍스트 처리와 대규모 배치가 동시에 요구되는 환경에서 하드웨어 역할 분리는 검토할 가치가 있는 방향이다.
다만 이 시스템은 아직 PoC 단계이며, “Studio Mesh”의 실제 정체와 스펙은 미검증이고, “first heterogeneous cluster”라는 주장은
마치며
이 설계의 핵심 가치는 하드웨어 이종성을 연산 특성의 비대칭성에 맞게 정렬한다는 점입니다. 프리필의 compute-bound 특성에는 Blackwell의 고밀도 연산 능력을, 디코드의 memory-bound 특성에는 대용량 RAM을 가진 노드를 배치하는 구조는 방향성 측면에서 합리적입니다. 국내 LLM 서비스 관점에서 시사점을 찾는다면, 이 아키텍처가 제기하는 질문은 다음과 같습니다: “동일 세대 GPU를 균일하게 확장하는 것이 항상 최선인가?” 긴 컨텍스트 처리와 대규모 배치가 동시에 요구되는 환경에서 하드웨어 역할 분리는 검토할 가치가 있는 방향입니다. 다만 이 시스템은 아직 PoC 단계이며, “Studio Mesh”의 실제 정체와 스펙은 미검증이고, “first heterogeneous cluster”라는 주장은 선행 사례 조사와 구현 증거가 뒷받침되어야 설득력을 얻을 수 있습니다. 그럼에도 불구하고, RDMA 전송 지연, 동적 메모리 관리, 장애 격리라는 세 가지 공학적 난제를 명확히 지목한 점은 실무자에게 유용한 체크리스트를 제공합니다.