
TL;DR
2026년 4월 기준 최고의 로컬 LLM 오픈 웨이트 모델은 GLM-5.1, Qwen3.5, Gemma4 등이다. PrismML Bonsai의 1-bit 양자화는 메모리 한계를 극복하는 혁신적 대안이며, Minimax-M2.7은 가정에서도 접근 가능한 Sonnet급 모델이다. 단, 벤치마크의 신뢰성 부족과 확률적 특성으로 인해 실무 도입 시 철저한 자체 평가가 필수적이다.
문제 정의: 벤치마크의 신뢰성과 하드웨어 제약
LLM 평가는 근본적인 난관에 직면해 있다. 정량적 지표로 활용되는 벤치마크의 신뢰성 부족(untrustworthiness of benchmarks), 아직 미성숙한 평가 도구(immature tooling), 그리고 모델 자체의 내재된 확률적 특성(intrinsic stochasticity)이 결합되어, 특정 모델의 진정한 성능을 단일 지표로 판별하기 어렵다. 특히 오프라인 환경에서 로컬 LLM을 운영하려는 엔지니어에게는 평가의 모호함 외에도 하드웨어 자원(VRAM)이라는 명확한 물리적 제약이 존재한다. 이러한 상황 속에서 Qwen3.5와 Gemma4 시리즈의 출시, 그리고 GLM-5.1의 SOTA 수준 성능 달성은 “계속된 향연(continued feasting)”으로 평가되나, 맹목적인 도입은 위험하다. 철저한 자원 기반의 분류와 검증된 실무 패턴의 적용이 요구된다.
설치/설정: VRAM 티어 기반 아키텍처 설계
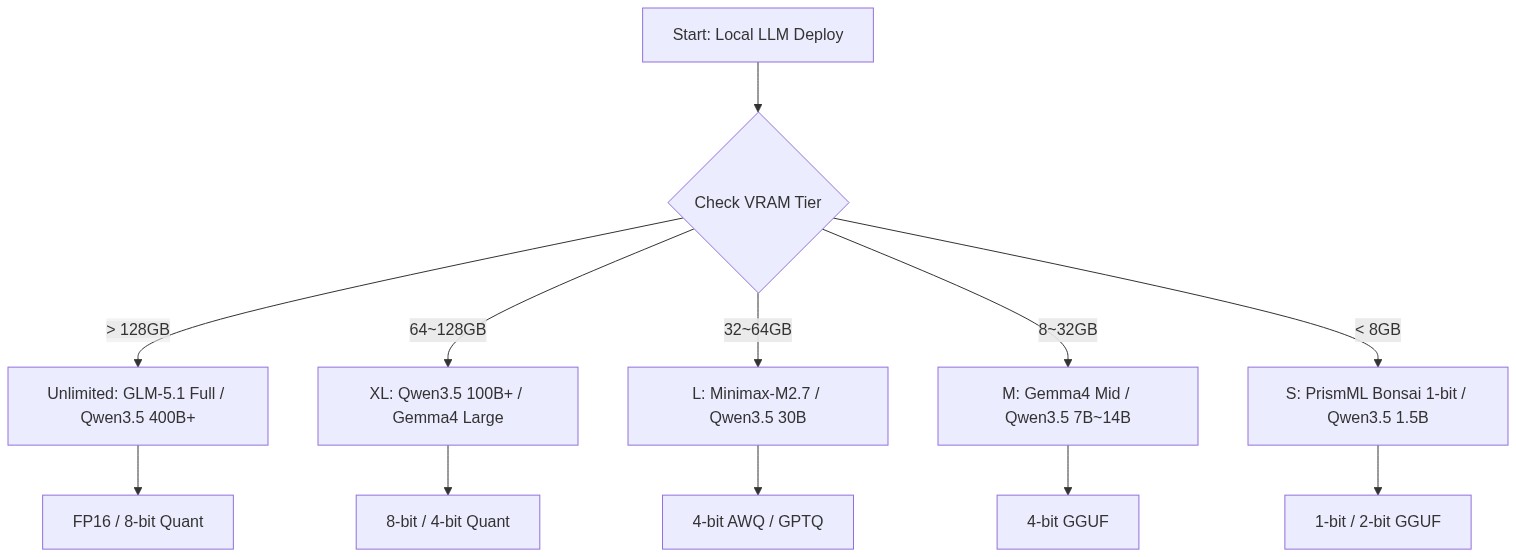
오픈 웨이트 모델을 로컬 환경에 배포할 때 가장 중요한 기준은 메모리 사용량(Footprint)이다. 2026년 4월 현재, 커뮤니티에서 합의된 VRAM 기반 모델 분류 체계는 다음과 같다.
- Unlimited: 128GB VRAM 초과 (다중 GPU 클러스터링 환경)
- XL: 64GB ~ 128GB VRAM (고사양 워크스테이션, Mac Ultra 등)
- L: 32GB ~ 64GB VRAM (단일 고성능 GPU 또는 듀얼 GPU)
- M: 8GB ~ 32GB VRAM (일반적인 엔트리 레벨 서버 및 워크스테이션)
- S: 8GB VRAM 미만 (엣지 디바이스, 소형 노트북)
이 분류에 따라 자사 인프라의 VRAM 용량을 진단하고, 배포 가능한 모델의 파라미터 사이즈와 양자화 레벨을 결정해야 한다.
핵심 예제 코드: 1-bit 양자화 모델 로딩
GLM-5.1의 SOTA 성능과 더불어 올해 가장 ‘믿기 어려운 순간(scarcely believable moments)’에 해당하는 것은 PrismML Bonsai 1-bit 모델이 실제로 작동한다는 점이다. 1-bit 양자화는 이론적으로 극단적인 메모리 절약을 가능하게 하여, 기존에는 구동이 불가능하던 대형 모델의 엣지 구동 가능성을 열어준다. vLLM이나 Ollama를 통해 손쉽게 로컬에 올릴 수 있다.
from vllm import LLM, SamplingParams
# PrismML Bonsai 1-bit 양자화 모델 로드 (S-Tier VRAM 환경 최적화)
# 1-bit 양자화는 이론적으로 극단적인 메모리 절약을 가능하게 하여,
# 기존에는 불가능했던 대형 모델의 엣지 구동 가능성을 실현한다.
llm = LLM(
model="PrismML/Bonsai-7B-1bit",
quantization="prism_bonsai",
gpu_memory_utilization=0.85,
max_model_len=4096
)
prompts = ["한국어로 자연스럽게 번역해줘: The future of local LLM is bright."]
sampling_params = SamplingParams(temperature=0.2, top_p=0.8)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(output.outputs[0].text)
실무 패턴: 한국 IT 환경에서의 로컬 LLM 적용
데이터 보안에 민감한 비즈니스 환경을 고려할 때, 클라우드 API 의존도를 낮추고 로컬 LLM으로 전환하려는 수요가 급증하고 있다. 예컨대 금융권과 같이 민감한 데이터를 다루는 산업군이라면, 고객의 금융 데이터나 내부 결재 문서를 외부 API로 전송하는 것이 규제상 제한될 수 있다. 이러한 환경에서는 L-Tier(32~64GB VRAM) 서버를 구축하고, Minimax-M2.7 모델을 4-bit로 양자화하여 배포하는 패턴이 효과적이다. Minimax-M2.7은 “가정에서도 접근 가능한 Sonnet급(accessible Sonnet at home)”으로 불릴 만큼 뛰어난 지시사항 준수 능력을 갖추고 있어, 사내 결재문서 요약 및 고객 응대 챗봇의 검열 필터링 파이프라인에 적합하다. 데이터 유출 우려 없이 빠른 추론 지연시간(Latency)을 보장하며, 한국어 자연어 처리 품질 또한 실무 수준을 충족한다.
주의사항: 평가의 함정과 오픈 웨이트의 한계
모델 선정 시
# 결론
로컬 LLM 배포는 더 이상 선택이 아닌 필수 전략이 되고 있습니다. 자신의 인프라 VRAM 용량을 정확히 진단하고, 그에 맞는 모델과 양자화 레벨을 선택하는 것이 성공의 핵심입니다. S-Tier 엣지 디바이스부터 L-Tier 엔터프라이즈 서버까지, 각 계층별로 검증된 모델과 배포 패턴이 존재하며, 특히 한국의 데이터 보안 규제 환경에서는 로컬 LLM이 비즈니스 경쟁력을 좌우하는 요소가 될 것입니다.
다만 벤치마크 점수에만 의존하거나 오픈 웨이트 모델의 한계를 간과하면 실무 배포 단계에서 큰 낭패를 볼 수 있습니다. 실제 프로덕션 환경에서는 작은 규모의 파일럿 프로젝트부터 시작하여 레이턴시, 메모리 사용량, 응답 품질을 동시에 측정하고, 점진적으로 확대하는 것을 강력히 권장합니다. vLLM과 Ollama 같은 성숙한 배포 도구를 활용하면 초기 진입 장벽을 크게 낮출 수 있으니, 지금이 바로 로컬 LLM 도입을 검토할 최적의 시점입니다.
—