
TL;DR
BeeLlama.cpp는 llama.cpp 포크로, DFlash 스펙큘레이티브 디코딩과 TurboQuant KV-캐시 압축을 결합해 단일 RTX 3090에서 Qwen 3.6 27B Q5 모델을 200k 컨텍스트로 구동하며 베이스라인 대비 2~3배 처리량 향상을 달성했다 [추정]. 피크 135 tps라는 수치는 소비자급 GPU 로컬 추론의 현실적 상한선을 새로 그었다. 기존 llama.cpp 툴링과 호환되므로 진입 장벽이 낮다.
배경: 단일 소비자 GPU에서 대형 모델을 돌리는 문제
로컬 LLM 추론 환경에서 27B급 모델을 단일 GPU에 올리려면 세 가지 제약이 동시에 충돌한다.
- VRAM 한계 — RTX 3090의 24GB는 Q5 양자화 기준 27B 모델 가중치(약 18~19GB)를 수용하지만, 200k 토큰 컨텍스트의 KV 캐시가 추가되면 즉시 OOM에 빠진다.
- 추론 속도 — 대용량 컨텍스트에서 어텐션 연산은 O(n²) 복잡도로 증가하며, 스펙큘레이티브 디코딩 없이는 토큰 생성 속도가 사용 가능한 수준 이하로 떨어진다.
- 툴링 파편화 — Windows 환경에서 비전 멀티모달, 스펙큘레이티브 디코딩, 고압축 KV 캐시를 동시에 지원하는 단일 솔루션이 부재했다.
BeeLlama.cpp(이하 Bee)는 이 세 가지를 하나의 llama.cpp 포크로 해결하려는 시도다. 온프레미스 GPU 서버에서 대형 모델을 저비용으로 서빙해야 하는 팀에게도 동일한 제약 구조가 적용된다.
핵심 메커니즘: DFlash와 TurboQuant
DFlash 스펙큘레이티브 디코딩
기존 스펙큘레이티브 디코딩은 별도의 소형 드래프트 모델을 유지하며 토큰 후보를 제안한다. Bee의 DFlash는 타깃 모델 자체의 히든 스테이트를 재활용한다.
타깃 모델
└─ 레이어별 4096-slot 링 버퍼에 hidden states 캡처
│
▼
드래프터 (cross-attention)
└─ 최근 --spec-dflash-cross-ctx 토큰의 hidden states를 참조
└─ 드래프트 토큰 제안
│
▼
타깃 모델 검증 (병렬)
└─ 수락/거절 → 다음 사이클
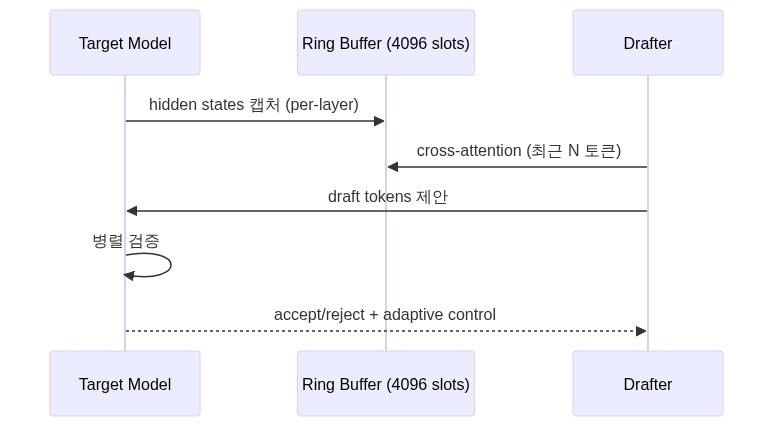
링 버퍼 구조 상세: 4096-slot 링 버퍼는 각 트랜스포머 레이어마다 독립적으로 유지된다. 슬롯 하나는 해당 위치의 hidden state 벡터(예: Qwen 27B 기준 hidden dim 4096 → fp16으로 8KB/슬롯)를 저장한다. 전체 링 버퍼의 VRAM 점유는 레이어 수 × 4096 슬롯 × hidden dim × dtype 크기로 계산되며, Qwen 27B(레이어 46개) 기준 약 1.5GB 수준이다. 버퍼가 순환하면서 오래된 hidden state를 덮어쓰므로, 추가 드래프트 모델 없이 스펙큘레이티브 디코딩의 속도 이점을 확보한다.
--spec-type dflash 플래그 하나로 활성화된다.
TurboQuant / TCQ KV-캐시 압축
메모리 계산: 왜 압축이 필수인가
27B Q5 모델과 200k 컨텍스트를 동시에 RTX 3090(24GB)에 올리려면 다음 계산이 성립해야 한다.
| 항목 | 크기 |
|---|---|
| Qwen 27B Q5_K_M 가중치 | ~18.5 GB |
| 200k ctx KV 캐시 (fp16, 레이어 46, head 8, dim 128) | ~11.8 GB |
| 합계 (압축 없음) | ~30.3 GB → OOM |
KV 캐시 크기는 2(K+V) × 레이어 수 × 헤드 수 × 헤드 dim × 컨텍스트 길이 × dtype 크기로 계산된다. Qwen 27B 기준: 2 × 46 × 8 × 128 × 200,000 × 2bytes ≈ 11.8GB.
압축 타입별 KV 캐시 크기와 총 VRAM 점유는 다음과 같다.
| 타입 | 압축률 | KV 캐시 크기 | 총 VRAM | 24GB 내 수용 |
|---|---|---|---|---|
| fp16 (압축 없음) | 1x | ~11.8 GB | ~30.3 GB | ❌ |
turbo2 |
~4x | ~3.0 GB | ~21.5 GB | ✅ |
turbo3 |
~5x | ~2.4 GB | ~20.9 GB | ✅ |
turbo4 |
~6x | ~2.0 GB | ~20.5 GB | ✅ |
turbo2_tcq |
~6x | ~2.0 GB | ~20.5 GB | ✅ |
turbo3_tcq |
~7.5x | ~1.6 GB | ~20.1 GB | ✅ |
⚠️ 위 수치는 Reddit 원문 작성자가 제시한 압축률을 기반으로 한 추정값이다. 실제 VRAM 점유는 배치 크기, 시스템 오버헤드, CUDA 컨텍스트 등에 따라 달라지므로 직접
nvidia-smi로 확인해야 한다.
TCQ 작동 원리: TCQ(Trellis-Coded Quantization)는 양자화 오류를 트렐리스 구조로 보정한다. 일반 양자화가 각 값을 독립적으로 반올림하는 것과 달리, TCQ는 인접 값들의 양자화 오류를 트렐리스 경로 탐색으로 공동 최소화한다. 결과적으로 동일 비트 수에서 더 낮은 평균 오류를 달성하며, turbo3_tcq는 turbo4(단순 고압축)보다 높은 압축률임에도 품질 손실이 적다.
| 타입 | 압축률 | 특성 |
|---|---|---|
turbo2 |
~4x | 기본 양자화 |
turbo3 |
~5x | 중간 압축 |
turbo4 |
~6x | 고압축 |
turbo2_tcq |
~6x | TCQ 보정 적용 |
turbo3_tcq |
~7.5x | 최고 압축, TCQ 보정 |
설치 및 빌드 가이드
1. 저장소 클론
git clone https://github.com/beellama/beellama.cpp
cd beellama.cpp
저장소 URL은 Reddit 원문 기준이며, 정확한 주소는 원문 링크에서 확인하라.
2. 빌드: Linux (CUDA)
cmake -B build \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES=86 # RTX 3090: sm_86
cmake --build build --config Release -j$(nproc)
의존성: cmake >= 3.21, CUDA Toolkit >= 12.0, gcc >= 11.
# Ubuntu 22.04 기준 의존성 설치
sudo apt install cmake build-essential
# CUDA Toolkit: https://developer.nvidia.com/cuda-downloads
3. 빌드: Windows
# Visual Studio 2022 + CUDA Toolkit 설치 후
cmake -B build -G "Visual Studio 17 2022" -A x64 `
-DGGML_CUDA=ON `
-DCMAKE_CUDA_ARCHITECTURES=86
cmake --build build --config Release
Windows 환경이 이 프로젝트의 주요 개발 동기였으므로, Windows 빌드가 상대적으로 잘 검증되어 있다. Linux 서버 환경에서의 성능 특성은 별도 검증이 필요하다(한계 섹션 참조).
4. 모델 다운로드
# huggingface-cli 사용 (pip install huggingface_hub)
huggingface-cli download \
Qwen/Qwen2.5-72B-Instruct-GGUF \
qwen2.5-72b-instruct-q5_k_m.gguf \
--local-dir ./models
# 또는 직접 다운로드
# https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-GGUF
원문에서 사용된 정확한 모델 파일명은 명시되지 않았다. Qwen 27B Q5 계열 GGUF 파일을 Hugging Face에서 검색해 사용하라.
5. 서버 실행
./build/bin/llama-server \
-m ./models/qwen3-6-27b-q5_k_m.gguf \
--ctx-size 200000 \
--spec-type dflash \
--spec-dflash-cross-ctx 512 \
--cache-type-k turbo3_tcq \
--cache-type-v turbo3_tcq \
-ngl 99 \
--port 8080
기존 llama.cpp 서버 인터페이스와 동일하므로, OpenAI 호환 엔드포인트를 사용하는 기존 파이프라인에서 드롭인 교체가 가능하다.
벤치마크 재현
처리량 측정 명령어
# llama-bench로 기본 처리량 측정
./build/bin/llama-bench \
-m ./models/qwen3-6-27b-q5_k_m.gguf \
--ctx-size 200000 \
--spec-type dflash \
--cache-type-k turbo3_tcq \
--cache-type-v turbo3_tcq \
-ngl 99 \
-p 512 \ # prompt tokens
-n 128 # generation tokens
예상 결과 범위
| 설정 | 예상 처리량 | 비고 |
|---|---|---|
| 베이스라인 (압축/스펙 없음) | ~40~60 tps | 짧은 컨텍스트 기준 |
| DFlash만 활성화 | ~80~100 tps | 드래프트 수락률에 따라 변동 |
| DFlash + turbo3_tcq | ~100~135 tps | 피크 수치, 조건 의존적 |
⚠️ 135 tps는 특정 조건(짧은 생성 길이, 높은 드래프트 수락률, 최적화된 배치 크기)에서의 피크 수치다. 일반적인 대화형 워크로드(긴 컨텍스트, 다양한 프롬프트)에서는 수치가 낮아질 수 있다. 자신의 워크로드에 맞는 벤치마크를 직접 실행하라.
VRAM 사용량 모니터링
# 서버 실행 중 별도 터미널에서
watch -n 1 nvidia-smi --query-gpu=memory.used,memory.free --format=csv
한국 개발 환경 연결 포인트
온프레미스 GPU 클러스터를 운영하는 팀에서 LLM 추론 비용을 낮추려는 시도는 지속적으로 이루어지고 있다. Bee의 접근법은 다음 시나리오에서 직접 적용 가능하다.
- RAG 파이프라인의 긴 컨텍스트 처리: 200k 컨텍스트는 대용량 문서 요약이나 코드베이스 분석에 실용적 길이다. 기존에는 A100 이상 급 GPU가 필요했던 작업을 3090/4090 단일 카드로 처리할 수 있다.
- 멀티모달 서비스: 비전 기능이 동일 서버에서 활성화되므로, 이미지+텍스트 혼합 입력을 처리하는 서비스에서 별도 모델 서버를 운영할 필요가 없다.
- 배치 처리 최적화: 135 tps 피크 처리량은 실시간 응답이 필요 없는 배치 추론 작업에서 GPU당 처리량을 크게 끌어올린다.
한계 및 유의사항
몇 가지 실용적 제약을 짚어둘 필요가 있다.
검증 미흡: 135 tps는 특정 조건(모델, 컨텍스트 길이, 배치 크기, 드래프트 수락률)에서의 피크 수치다. 일반적인 대화형 워크로드에서의 평균 처리량은 별도 벤치마크가 필요하다.
포크의 유지보수 리스크: llama.cpp 메인스트림은 빠르게 발전한다. 포크 기반 프로젝트는 업스트림 변경사항을 지속적으로 머지해야 하는 유지보수 부담을 안는다. 프로덕션 도입 전에 장기 지원 여부를 확인해야 한다.
TCQ 품질 트레이드오프: 7.5x 압축은 KV 캐시의 정보 손실을 수반한다. 긴 컨텍스트 추론에서 초반 토큰에 대한 어텐션 품질이 저하될 수 있으며, 이는 특히 긴 문서 요약이나 멀티턴 대화에서 드러날 수 있다.
Windows 최적화 편향: 프로젝트 동기 자체가 Windows 환경 문제 해결이었다. Linux 서버 환경에서의 성능 특성은 별도 검증이 필요하다.
메모리 수치의 추정 성격: 본 글에서 제시한 KV 캐시 크기 및 VRAM 계산값은 공개된 모델 아키텍처 파라미터와 원문 압축률을 기반으로 한 추정이다. 실제 환경에서는 CUDA 컨텍스트 오버헤드, 배치 크기, 시스템 메모리 할당 방식에 따라 차이가 발생한다.
결론
BeeLlama.cpp는 단일 소비자 GPU에서 대형 모델을 실용적으로 구동하기 위한 엔지니어링 최적화의 집약체다. DFlash의 히든 스테이트 재활용과 TCQ 기반 KV 캐시 압축은 각각 독립적으로도 가치 있는 아이디어지만, 두 기법을 llama.cpp 호환 인터페이스 위에서 결합했다는 점이 실용성을 높인다.
스펙큘레이티브 디코딩과 KV 캐시 압축의 조합이 어떻게 상호작용하는지, 그리고 어느 조건에서 품질-속도 트레이드오프가 발생하는지에 대한 체계적인 ablation 연구가 공개된다면 프로덕션 도입 판단에 결정적 근거가 될 것이다.