
TL;DR
MTP와 TurboQuant를 결합한 LLM 추론 최적화 기법을 통해 단일 RTX 4090 24GB 환경에서 Qwen3.6-27B 모델을 초당 80 토큰 이상으로 구동하는 데 성공했다. MTP(Medusa Tree Prediction)의 약 73% 드래프트 수락률과 TurboQuant의 4.25 bpv 무손실 KV 캐시 압축이 시너지를 내어 262K 컨텍스트 조건에서 속도가 43 t/s에서 80-87 t/s로 약 2배 향상되었다. 이는 제한된 VRAM 환경에서 장문 처리가 필요한 실무 온프레미스 시나리오에 즉각적인 적용 가능성을 시사한다.
문제 정의: 단일 GPU에서의 장문 컨텍스트 추론 병목
27B 파라미터급 대형 언어 모델을 소비자용 단일 GPU(24GB VRAM)에서 구동할 때의 가장 큰 장벽은 메모리 한계와 디코딩 병목이다. 특히 262K에 달하는 장문 컨텍스트를 처리할 경우, KV 캐시가 VRAM 대부분을 점유하여 모델 가중치 적재 자체가 불가능해지거나 초당 토큰 생성 속도(Tokens per second)가 급격히 저하된다. 기존의 Q4_K_M 양자화는 모델 가중치의 크기를 줄이는 데는 효과적이지만, 런타임에 생성되는 KV 캐시의 메모리 폭발을 통제하지 못한다. 이 상태에서 Speculative Decoding을 통한 속도 향상을 시도하면 메모리 여유가 없어 드래프트 모델의 추가 로딩이 불가능해진다. 이러한 구조적 병목을 해결하기 위해 저자는 MTP 헤드 이식과 KV 캐시 무손실 압축을 동시에 적용하는 접근법을 취했다.
설치 및 설정: llama.cpp-mtp 포크 기반 구동
해당 실험은 공식 llama.cpp가 아닌, MTP 지원을 위해 커스텀 수정된 포크 버전을 기반으로 진행되었다. 시스템은 Ubuntu 24.04와 CUDA 12.x 환경에서 구축되었다.
빌드 방법
아래 명령어로 MTP+TurboQuant 포크를 클론하고 CUDA 지원으로 컴파일한다.
# 1. MTP+TurboQuant 지원 포크 클론
git clone https://github.com/Nexesenex/croco.cpp.git llama.cpp-mtp
cd llama.cpp-mtp
# 2. CUDA 지원 빌드 (cmake)
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_CUDA_F16=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j$(nproc)
# 3. 빌드 결과물 확인
ls build/bin/llama-server
주의: CUDA 12.x와 cuDNN이 사전 설치되어 있어야 한다.
nvidia-smi로 드라이버 버전을 확인하고,nvcc --version으로 CUDA 툴킷 버전을 검증한 뒤 진행한다.DGGML_CUDA_F16=ON플래그는 RTX 4090의 FP16 텐서 코어를 활용하기 위해 필수적이다.
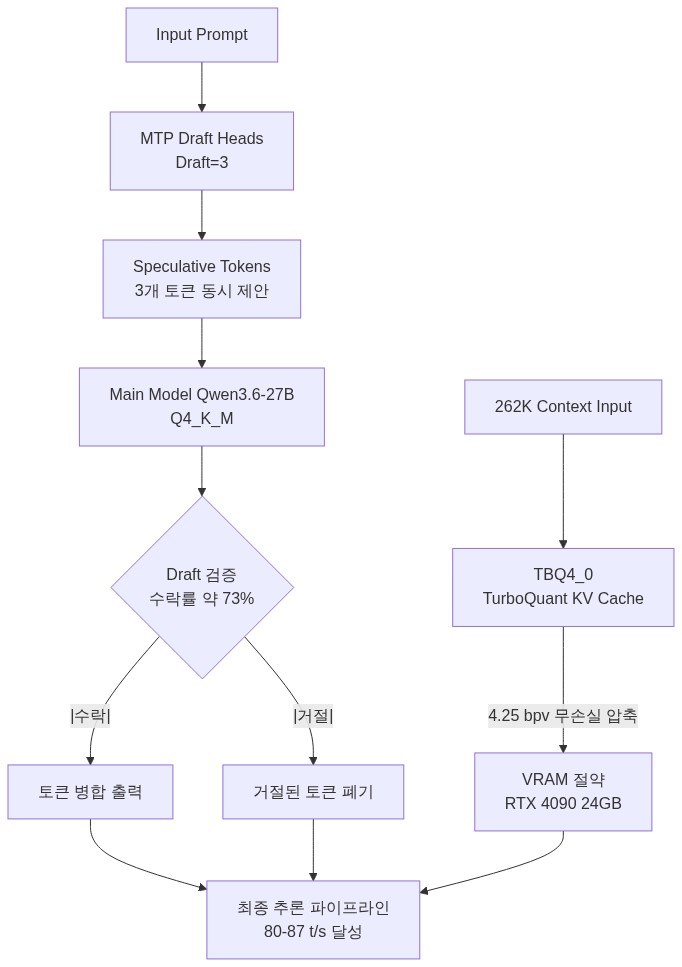
아키텍처 다이어그램에서 볼 수 있듯, MTP가 드래프트 토큰을 제안하여 연산 병렬성을 높이는 동안, TBQ4_0는 262K 컨텍스트가 생성하는 방대한 KV 캐시를 4.25 bpv로 압축하여 VRAM 여유 공간을 확보한다. 이 두 기술이 결합되지 않으면 단일 4090에서 262K 컨텍스트 기반 구동 자체가 불가능하다.
핵심 예제 코드: MTP 및 TBQ4_0 실행 파라미터
모델은 Qwen3.6-27B-Heretic-v2 Q4_K_M 양자화 버전에 MTP 헤드가 이식(grafted)된 변형을 사용한다. 컴파일된 포크 빌드에서 다음과 같은 파라미터로 서버를 구동한다.
./build/bin/llama-server \
-m Qwen3.6-27B-Heretic-v2-Q4_K_M-MTP.gguf \
-c 262000 \
-tbq 4 \
--mtp-draft 3 \
-ngl 99 \
-t 8
위 명령어에서 -c 262000은 262K 컨텍스트 윈도우를 할당함을 의미한다. -tbq 4는 TurboQuant의 4.25 bpv 무손실 KV 캐시(TBQ4_0)를 활성화하는 핵심 플래그다. --mtp-draft 3은 MTP 헤드가 한 번에 3개의 드래프트 토큰을 제안하도록 설정하여 병렬 디코딩 깊이를 지정한다.
MTP 수락률과 이론적 속도 향상 계산
MTP의 실질적인 속도 향상은 드래프트 수락률 α와 드래프트 깊이 k에 의해 결정된다. 드래프트 토큰이 독립적으로 수락된다고 가정할 때, 한 번의 검증 스텝에서 기대되는 수락 토큰 수 E[accepted]는 다음과 같다.
드래프트 깊이 k=3, 수락률 α=0.73 일 때:
E[accepted] = Σ(i=1 to k) α^i
= α + α² + α³
= 0.73 + 0.5329 + 0.3890
≈ 1.652 토큰/스텝
검증 스텝당 실제 출력 토큰 수 = E[accepted] + 1 (검증 토큰 포함)
≈ 2.652 토큰/스텝
이론적 속도 향상 배율 = 2.652 / 1 ≈ 2.65×
단, 이는 드래프트 헤드의 추가 연산 오버헤드를 제외한 상한값이다. 실제 측정된 43 t/s → 80-87 t/s는 약 1.9-2.0× 향상으로, 드래프트 헤드 연산 비용과 거절 시 롤백 오버헤드를 감안하면 이론치에 근접한 합리적인 결과다.
거절 시 롤백 메커니즘: 수락률 27%에 해당하는 거절 케이스에서는 첫 번째 불일치 위치까지의 드래프트 토큰이 폐기되고, 메인 모델이 해당 위치부터 재생성을 시작한다. 롤백 자체의 연산 비용은 낮지만, 거절이 연속으로 발생하는 구간(예: 모델이 예측하기 어려운 고유명사, 코드 리터럴)에서는 순간적인 레이턴시 스파이크가 발생할 수 있다.
실무 패턴: 한국 IT 서비스 환경에서의 활용 가능성
MTP와 TurboQuant를 결합한 LLM 추론 최적화는 온프레미스 AI 도입을 검토하는 국내 IT 기업에 실질적인 대안을 제시한다. 예컨대 토스와 같은 핀테크 서비스는 고객의 금융 데이터를 외부 클라우드 API로 전송할 수 없으므로, 내부 망에서 LLM을 구동해야 하는 강력한 규제적 제약이 존재한다. 이때 수십만 원 어치의 금융 계약서나 규제 문서(262K 이상)를 입력해 실시간으로 요약하고 분석하려면 막대한 GPU 인프라가 필요하다.
단일 RTX 4090에서 27B급 모델이 80 t/s 이상의 속도를 낸다는 것은, 고가의 H100 클러스터를 대여하지 않고도 워크스테이션 급 장비로 실시간에 가까운 문서 분석 파이프라인을 구축할 수 있음을 의미한다. MTP의 73% 수락률은 드래프트 재계산으로 인한 레이턴시 스파이크를 제어할 수 있는 수준이며, TBQ4_0의 무손실 압축은 금융/법률 도메인에서 민감한 정밀도 저하를 방지한다는 점에서 실무 적용 가치가 충분하다.
한국어 컨텍스트에서의 MTP/TBQ4_0 성능 변화 가설
그러나 위 벤치마크가 영어 기반 텍스트에서 측정되었다는 점은 국내 적용 시 반드시 고려해야 할 변수다. 한국어 특성은 MTP와 TBQ4_0 양쪽 모두에 비대칭적인 영향을 미칠 가능성이 높다.
MTP 수락률 저하 가설: 한국어는 교착어(agglutinative language) 특성상 조사·어미의 결합으로 하나의 어절이 다수의 서브워드 토큰으로 분리된다. 예컨대 “처리하였습니다”는 BPE 토크나이저 기준으로 4-6개 토큰으로 분절될 수 있으며, 각 토큰의 조건부 확률 분포가 영어 단어 단위보다 훨씬 좁고 결정론적이다. 이는 역설적으로 MTP 수락률을 높이는 방향으로 작용할 수 있다. 반면 한자어 고유명사(예: 금융감독원, 신용보증기금)나 법령 조문 번호(제17조제2항제3호)처럼 예측 불가능한 시퀀스에서는 수락률이 영어 대비 더 급격히 떨어질 것으로 예상된다.
TBQ4_0 압축 효율 변화 가설: 한국어 법률·금융 문서는 반복적인 조사 패턴과 정형화된 문장 구조를 가지므로, KV 캐시 내 어텐션 패턴의 엔트로피가 영어보다 낮을 가능성이 있다. 이 경우 TBQ4_0의 4.25 bpv 압축이 한국어 문서에서 더 높은 효율을 보일 수 있다. 그러나 이는 어디까지나 가설이며, 실제 검증을 위해서는 다음과 같은 벤치마크가 필요하다.
[제안 벤치마크 설계]
- 데이터셋: 금융감독원 공시 문서, 법원 판결문 (각 50K~262K 토큰 범위)
- 측정 지표:
1. MTP 수락률 (한국어 vs 영어 동일 도메인 비교)
2. TBQ4_0 실효 압축률 (bpv 단위)
3. 토큰/초 (컨텍스트 길이별: 32K / 128K / 262K)
4. 거절 집중 구간 분석 (어떤 토큰 유형에서 롤백이 발생하는지)
- 비교군: 동일 하드웨어에서 TBQ4_0 미적용 + MTP 미적용 베이스라인
이 벤치마크 결과가 확보된다면, 국내 핀테크·리걸테크 기업이 온프레미스 도입 여부를 결정하는 데 있어 훨씬 구체적인 근거를 제공할 수 있다.
주의사항: 실험적 접근과 검증의 한계
저자 역시 밝혔듯이 이 결과는 “vibecoding”에 가까운 직관적 실험의 산물이며, 완성된 프로덕션급 솔루션이 아니다. 우선 단일 RTX 4090 24GB 환경과 특정 모델 변형(Qwen3.6-27B-Heretic-v2 Q4_K_M)에 국한된 벤치마크이므로, 다른 아키텍처나 파라미터 스케일에서 동일한 성능 향상을 보장할 수 없다.
또한 73%의 MTP 드래프트 수락률은 준수한 수치이나, 거절된 27%의 토큰에 대한 롤백 및 재계산 과정이 트래픽이 몰리는 실서비스 환경에서 P99 레이턴시에 어떤 영향을 미치는지는 별도의 부하 테스트가 필요하다. TBQ4_0의 4.25 bpv 압축이 ‘무손실’을 표방하나, 장기간 연속 구동 시 미세한 정밀도 드리프트가 누적될 가능성 역시 배제할 수 없다. 커널 아키텍처의 기술적 세부사항은 저자의 추가 블로그 포스트를 참조해야 한다.
결론
MTP와 TurboQuant를 결합한 LLM 추론 최적화는 로컬 하드웨어의 한계를 극복하는 유의미한 이정표를 제시했다. 43 t/s에서 80-87 t/s로의 속도 도약과 262K 컨텍스트 처리 능력은 소비자용 GPU에서 27B 모델의 실서비스 수준 구동이 가능함을 입증했다. 아직 커널 레벨의 개선 여지와 다양한 환경에서의 재현성 검증이 남아있으나, 온프레미스 LLM 파이프라인을 설계하는 백엔드/ML 엔지니어에게 즉각적인 아키텍처 영감을 제공하는 결과다.
출처: Got MTP + TurboQuant running — Qwen3.6-27B — 80+ t/s at 262K context on a single RTX 4090