
TL;DR
Wikimedia Enterprise API는 LLM 학습 및 AI 서비스 구축에 Wikipedia 데이터를 공식적으로 활용할 수 있는 유료 엔터프라이즈 채널이다. 공개된 공식 문서 범위 내에서, MediaWiki Action API(무료)와의 차이점 및 실무 적용 가능성을 검토한다. 미검증 API 스펙은 이 포스트에서 다루지 않는다.
문제 정의: Wikipedia 데이터를 AI에 쓰려면 무엇이 문제인가
Wikipedia는 전 세계 LLM 사전학습 데이터셋의 핵심 소스다. Common Crawl 기반 데이터셋(C4, The Pile 등)에서도 Wikipedia 텍스트는 별도 추출·포함되는 경우가 많다(C4의 경우 Wikipedia는 Common Crawl과 별도로 혼합되며, The Pile에서는 독립 서브셋으로 포함된다). 그러나 Wikipedia 데이터를 프로덕션 AI 서비스에 통합하려는 팀이 실제로 마주치는 문제는 세 가지다.
- 데이터 신선도: Wikimedia 재단이 제공하는 공개 덤프(XML dump)는 월 1~2회 갱신된다 [추정]. 실시간 검색 보강(RAG) 파이프라인에서는 수용 불가능한 지연이다.
- 스케일과 안정성: 무료 MediaWiki Action API는 비상업적 용도를 전제로 설계되어 있고, 대규모 배치 요청 시 속도 제한(rate limit)에 즉시 걸린다.
- 법적 명확성: CC BY-SA 라이선스 준수, attribution 의무, 상업적 이용 조건을 내부 법무팀이 검토할 수 있는 계약 구조가 필요하다.
Wikimedia Enterprise는 이 세 가지 문제를 상업 계약 기반으로 해소하겠다는 포지셔닝이다.
설치/설정: 실제로 사용할 수 있는 공개 API부터 시작하기
Wikimedia Enterprise의 상세 API 스펙, 엔드포인트 구조, 응답 스키마는 계약 이후 접근 가능한 문서에 있으며, 공개 페이지에서는 확인되지 않는다. 따라서 이 섹션에서는 공식 문서가 검증된 MediaWiki REST API를 기준으로 작동 방식을 먼저 파악하는 접근을 권장한다.
import httpx
import json
# MediaWiki REST API (공식 문서 확인 가능, 무료)
# 출처: https://www.mediawiki.org/wiki/API:REST_API
BASE_URL = "https://en.wikipedia.org/w/rest.php/v1"
def fetch_article_summary(title: str) -> dict:
"""
공식 MediaWiki REST API를 통한 문서 요약 조회.
Wikimedia Enterprise는 이 레이어 위에서
상업적 SLA와 고처리량을 보장하는 구조로 알려져 있다.
"""
url = f"{BASE_URL}/page/{title}/with_html"
headers = {
"User-Agent": "MyRAGBot/1.0 (contact@example.com)" # 필수
}
resp = httpx.get(url, headers=headers, timeout=10.0)
resp.raise_for_status()
data = resp.json()
return {
"title": data.get("title"),
"revision_id": data.get("latest", {}).get("id"),
"source": data.get("source"), # 위키텍스트 원문
}
# 한국어 Wikipedia 동일 패턴 적용
KO_BASE_URL = "https://ko.wikipedia.org/w/rest.php/v1"
def fetch_ko_article(title: str) -> dict:
url = f"{KO_BASE_URL}/page/{title}/with_html"
headers = {"User-Agent": "MyRAGBot/1.0 (contact@example.com)"}
resp = httpx.get(url, headers=headers, timeout=10.0)
resp.raise_for_status()
return resp.json()
주의:
User-Agent헤더 누락 시 요청이 차단될 수 있다. Wikimedia 정책상 봇 식별 정보는 필수다.
핵심 구조: Enterprise vs 공개 API 비교
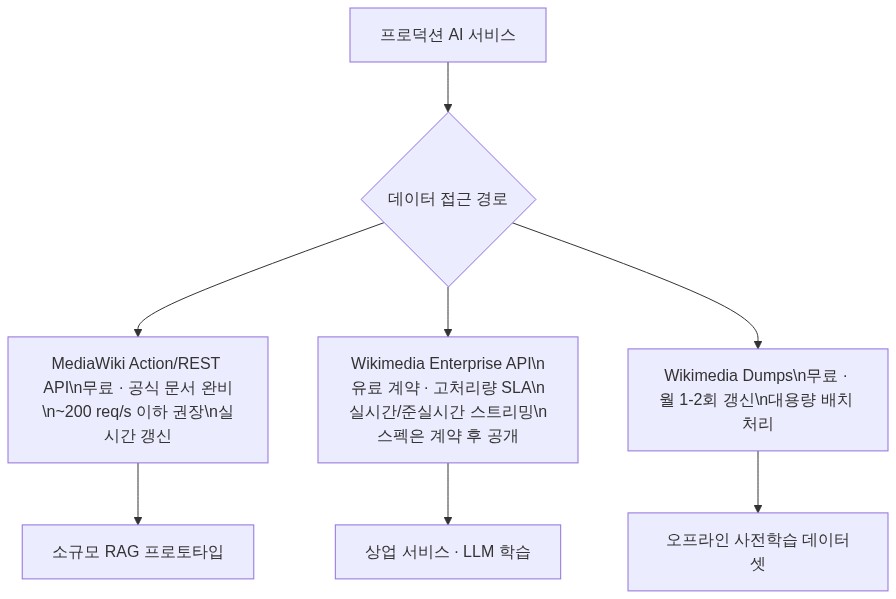
공개 API와 Enterprise의 차이는 단순히 “유료 vs 무료”가 아니다. 아래 표는 공식 문서 및 Wikimedia Enterprise 소개 페이지에서 확인 가능한 항목만을 기준으로 정리한 것이다.
| 항목 | MediaWiki REST API (무료) | Wikimedia Dumps (무료) | Wikimedia Enterprise (유료) |
|---|---|---|---|
| Rate Limit | 비인증 기준 약 200 req/s 미만, 대규모 배치 시 429 즉시 반환 | 해당 없음 (파일 다운로드) | 계약 기반 고처리량 SLA (구체적 수치는 계약 후 공개) |
| 갱신 주기 | 실시간 (편집 즉시 반영) | 월 1~2회 | 실시간 스트리밍 또는 준실시간 (Wikimedia 공식 페이지 기준) |
| 캐싱 레이어 | CDN 캐시 (Varnish), TTL 미보장 | 해당 없음 | 전용 캐싱 인프라 (SLA 보장) |
| 응답 포맷 | JSON (위키텍스트, HTML) | XML, SQL 덤프 | JSON (구조화, 정규화된 스키마) |
| Attribution 의무 | CC BY-SA 4.0 준수 필요 | CC BY-SA 4.0 준수 필요 | CC BY-SA 4.0 준수 필요 (계약으로 명문화) |
| 상업적 이용 | 기술적으로 가능, 법적 계약 없음 | 기술적으로 가능, 법적 계약 없음 | 계약 기반 법적 명확성 확보 |
Rate Limiting 실측 맥락: 무료 MediaWiki API에서 비인증 대규모 배치 요청 시 일반적으로 수백 req/min 수준에서 429 응답이 반환되기 시작한다. Wikimedia의 공식 봇 정책(Wikimedia Bot Policy)에 따르면 봇 계정 인증 후에도 초당 요청 수에 제한이 있으며, 프로덕션 수준의 병렬 처리에는 적합하지 않다.
실무 패턴: 한국 서비스 환경에서의 고려사항
한국어 Wikipedia의 데이터 품질 격차는 실무에서 반드시 인지해야 할 변수다. Wikimedia 공식 통계(stats.wikimedia.org)에 따르면, 2024년 기준 한국어 Wikipedia의 문서 수는 약 680,000개로, 영어판(약 6,800,000개)의 약 10% 수준이다. 단, 문서 수 자체보다 실질적인 커버리지 격차가 더 크다. 한국어 문서 중 상당수는 스텁(stub) 수준의 짧은 문서이며, 전문 기술 문서나 지역 특화 정보의 심도 있는 서술은 영어판 대비 현저히 낮다.
수치 참고: 이 포스트 작성 시점 기준 stats.wikimedia.org의 “Total articles” 항목을 직접 확인할 것을 권장한다. 문서 수는 지속적으로 증가하므로 독자가 접근하는 시점의 수치와 차이가 있을 수 있다.
이 때문에 네이버, 카카오 등 국내 플랫폼에서 지식 베이스를 구성할 때 Wikipedia 단독 의존은 실질적으로 불가능하다. 실제 RAG 파이프라인을 구성한다면 다음 레이어 구조가 현실적이다.
# 다중 소스 RAG 파이프라인 예시 (개념 구조)
# 의사결정 기준: 쿼리 언어, 도메인, 요구 신선도를 기준으로 소스 라우팅
from dataclasses import dataclass
from typing import Optional
@dataclass
class KnowledgeSource:
name: str
coverage: str
freshness: str
avg_latency_ms: int # 예상 응답 지연 (개념적 추정치)
ko_doc_coverage: str # 한국어 문서 커버리지 평가
KNOWLEDGE_SOURCES = [
KnowledgeSource("wikipedia_ko", "general", "monthly", 200, "중 (약 68만 문서, 스텁 비율 높음)"),
KnowledgeSource("naver_encyclopedia","ko_specific", "realtime", 150, "높음 (한국어 특화, 전문 문서 풍부)"),
KnowledgeSource("internal_docs", "domain_specific","realtime", 50, "도메인 한정"),
]
def route_query(query: str, lang: str = "ko", domain: Optional[str] = None) -> list[str]:
"""
한국어 쿼리 라우팅 전략:
- 한국어 특화 정보(인물, 지역, 문화): naver_encyclopedia 우선
- 글로벌 일반 지식: wikipedia_ko 우선 (단, 스텁 문서 필터링 필요)
- 도메인 특화(내부 문서 있는 경우): internal_docs 최우선
실제 구현 시 각 소스의 문서 길이, 최종 수정일을 메타데이터로
활용해 소스 신뢰도를 동적으로 조정하는 것을 권장한다.
"""
sources = []
if domain and domain in ["internal", "product"]:
sources.append("internal_docs")
return sources # 내부 문서로 충분한 경우 외부 소스 불필요
if lang == "ko":
sources.append("naver_encyclopedia") # 한국어 커버리지 보완
sources.append("wikipedia_ko")
sources.append("internal_docs")
return sources
도입 의사결정 매트릭스
Wikimedia Enterprise 도입 여부는 서비스 특성에 따라 ROI가 크게 달라진다. 아래 매트릭스는 공개된 정보 범위 내에서 구성한 의사결정 기준이다. 가격은 공개되지 않으므로 비용 항목은 상대적 비교로만 표시한다.
| 서비스 유형 | 주요 언어 | Wikipedia 커버리지 | 신선도 요구 | Enterprise 도입 권고 | 대안 |
|---|---|---|---|---|---|
| 글로벌 뉴스 요약 / 팩트체크 | 영어 | 높음 | 높음 (실시간) | 강력 권고 | 무료 API (rate limit 위험) |
| 영어 교육 / 백과사전 서비스 | 영어 | 높음 | 낮음 (월 단위 수용) | Dumps로 대체 가능 | XML Dump + 자체 파이프라인 |
| 한국어 일반 지식 QA | 한국어 | 중간 (스텁 비율 고려) | 중간 | 보완 소스 설계 선행 필요 | 네이버 지식백과 + Wikipedia |
| 한국어 특화 도메인 (법률, 의료 등) | 한국어 | 낮음 | 높음 | Wikipedia 의존 부적합 | 도메인 전문 DB 우선 |
| 다국어 LLM 사전학습 | 다국어 | 영어 중심 높음 | 낮음 (배치) | Enterprise 또는 Dumps | Dumps (비용 절감) |
핵심 의사결정 기준 요약:
– 신선도 요구가 높고 영어 중심 서비스: Enterprise의 실시간 스트리밍이 명확한 가치를 제공한다.
– 한국어 특화 서비스: Enterprise 도입 전 한국어 문서 커버리지를 쿼리 샘플로 직접 측정하고, 미충족 비율이 30% 이상이면 보완 소스 설계를 병행해야 한다.
– 배치 사전학습 전용: Dumps가 비용 대비 효율적이며, Enterprise의 추가 비용을 정당화하기 어렵다.
Wikimedia Enterprise를 도입한다면, 한국어 데이터의 실질적 커버리지 한계를 계약 전에 평가하는 것이 선행되어야 한다. 영어권 콘텐츠 중심 서비스(글로벌 뉴스 요약, 영어 교육 등)에서는 ROI가 명확하지만, 한국어 특화 서비스에서는 보완 소스 설계가 필수다.
주의사항
| 항목 | 내용 |
|---|---|
| API 스펙 검증 | 공개 문서에서 엔드포인트 구조 미확인. 계약 전 PoC 환경 요청 권장 |
| 라이선스 | CC BY-SA 4.0 의무 준수. Enterprise 계약도 attribution 의무는 유지됨 |
| 한국어 커버리지 | 영어판 대비 문서 수 약 10% 수준, 스텁 비율 고려 시 실질 격차 더 큼. 단독 의존 구조는 위험 |
| 속도 제한 | 무료 API는 대규모 배치에 부적합. Enterprise 계약 시 SLA 조건 명시 요청 필요 |
| 가격 정책 | 공개 페이지에서 확인 불가. 직접 문의 필요 |
결론
Wikimedia Enterprise API는 Wikipedia 데이터를 LLM 학습 또는 상업적 RAG 파이프라인에 통합하려는 팀에게 법적 명확성과 운영 안정성을 제공하는 채널로 포지셔닝되어 있다. 그러나 공개된 기술 문서가 제한적이므로, 도입 검토 단계에서는 반드시 Wikimedia 측에 PoC 환경과 상세 스펙 문서를 요청해야 한다.
한국어 서비스 환경에서는 Wikipedia 단독 의존의 커버리지 한계를 먼저 정량적으로 평가하고, 보완 소스와의 멀티-레이어 설계를 병행하는 것이 현실적인 접근이다. 검증되지 않은 API 스펙을 전제로 아키텍처를 설계하는 것은 프로덕션 리스크로 직결된다.
출처
– Wikimedia Enterprise 공식 페이지: https://enterprise.wikimedia.com/
– MediaWiki REST API 공식 문서: https://www.mediawiki.org/wiki/API:REST_API
– Wikimedia Bot Policy: https://www.mediawiki.org/wiki/Manual:Bot_passwords
– Wikimedia 통계 대시보드: https://stats.wikimedia.org