
TL;DR
vLLM ROCm 백엔드가 Lemonade에 실험적으로 통합되어, AMD GPU 환경에서 .safetensors 형식의 LLM을 GGUF 변환 없이 직접 실행할 수 있게 되었다. 필수 기능은 구현되었으나 알려진 문제점이 존재하며, 개발 방향은 커뮤니티 피드백에 의존한다. llama.cpp 수준의 단순한 CLI 인터페이스를 제공한다는 점이 주목할 만하다.
배경: GGUF 변환 없이 LLM을 실행한다는 것의 의미
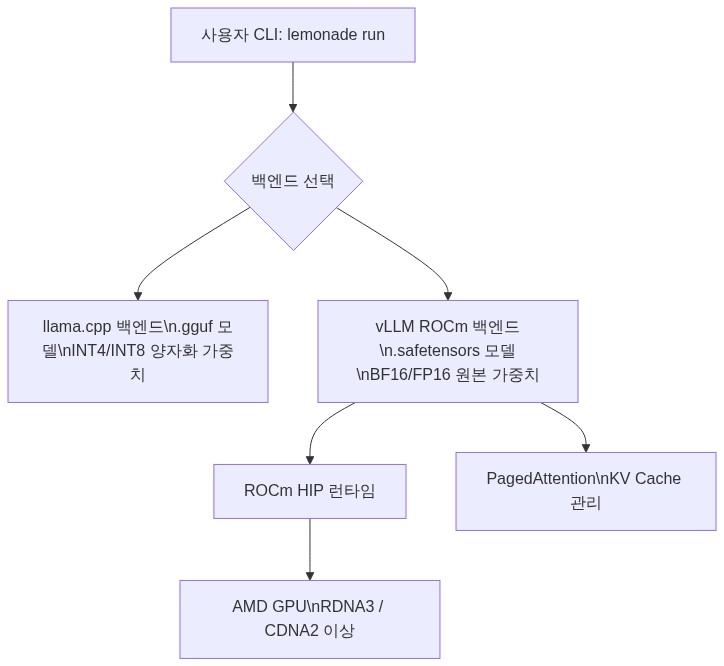
현재 로컬 LLM 실행 생태계는 크게 두 갈래로 나뉜다. llama.cpp 계열은 .gguf 형식으로 양자화된 모델을 CPU/GPU 혼합 환경에서 실행하는 방식이고, vLLM은 HuggingFace의 .safetensors 형식을 그대로 읽어 PagedAttention 기반으로 서빙하는 방식이다.
문제는 Hugging Face에 공개된 대부분의 최신 모델이 .safetensors 형식이라는 점이다. 이를 llama.cpp 생태계에서 사용하려면 GGUF 변환 → 양자화 단계를 거쳐야 하며, 이 과정에서 정밀도 손실, 변환 실패, 아키텍처 미지원 등의 문제가 빈번하게 발생한다. 특히 신규 아키텍처 모델(예: Qwen3, Gemma3 계열)은 llama.cpp의 GGUF 변환 지원이 수 주 뒤처지는 경우가 많다.
vLLM은 이 문제를 우회한다. 모델을 변환하지 않고 원본 가중치 그대로 실행하기 때문에, 모델 출시 직후부터 바로 추론이 가능하다.
핵심 메커니즘: Lemonade + vLLM ROCm 아키텍처
Lemonade는 로컬 LLM 실행을 위한 커뮤니티 툴킷으로, 기존에는 llama.cpp를 주된 백엔드로 사용해왔다. 이번 업데이트는 vLLM의 ROCm 빌드를 Lemonade의 새로운 실험적 백엔드로 추가한 것이다. AMD가 공식적으로 배포하거나 보증하는 제품이 아니며, 원문 발표 역시 커뮤니티 채널(Reddit)을 통해 이루어졌다는 점을 유의해야 한다.
설치 및 실행은 두 줄로 완결된다.
# vLLM ROCm 백엔드 설치
lemonade backends install vllm:rocm
# Qwen3.5-0.8B 모델 실행 (safetensors 직접 로드)
lemonade run Qwen3.5-0.8B-vLLM
기존 llama.cpp 워크플로우와 인터페이스가 동일하다는 점이 핵심이다. 백엔드가 교체되더라도 상위 레이어의 CLI 사용법은 변하지 않는다. 이는 llama.cpp와 vLLM을 A/B 비교하거나, 특정 모델에 맞는 백엔드를 선택적으로 사용하는 워크플로우를 가능하게 한다.
.safetensors 직접 로드의 기술적 의미
.safetensors는 HuggingFace가 설계한 가중치 저장 포맷으로, 텐서의 dtype과 메모리 레이아웃을 변환 없이 그대로 보존한다. 일반적으로 BF16 또는 FP16 정밀도로 저장된 원본 가중치를 그대로 GPU 메모리에 올린다. 반면 GGUF 변환 과정에서는 INT4(Q4_K_M 기준) 또는 INT8 양자화가 적용되어, 이론적으로 각각 약 75%, 50%의 정밀도 비트 수 감소가 발생한다. 이 손실이 실제 태스크 성능에 미치는 영향은 모델과 태스크에 따라 다르지만, 수학적 추론이나 코드 생성처럼 정밀도에 민감한 태스크에서 차이가 두드러지는 경향이 있다.
메모리 요구량 측면에서는 반대 트레이드오프가 존재한다. BF16 기준 7B 파라미터 모델은 약 14GB VRAM을 필요로 하는 반면, Q4_K_M 양자화 시 약 4~5GB로 줄어든다. .safetensors 직접 로드는 정밀도를 보존하는 대신 충분한 VRAM을 전제로 한다.
PagedAttention의 동작 방식
vLLM의 PagedAttention은 KV 캐시를 운영체제의 가상 메모리 페이지 방식으로 관리한다. 기존 방식에서는 각 시퀀스에 대해 최대 컨텍스트 길이만큼의 연속 메모리 블록을 사전 할당하기 때문에, 실제 사용되지 않는 영역이 낭비되고 메모리 단편화가 심해진다. PagedAttention은 KV 캐시를 고정 크기의 비연속 블록(page)으로 분할하여 필요한 만큼만 동적으로 할당함으로써, 이론적으로 KV 캐시 메모리 낭비를 거의 0에 가깝게 줄인다. 이 효과는 단일 사용자 로컬 실행보다 다중 요청이 동시에 처리되는 서빙 시나리오에서 두드러진다.
ROCm 환경에서의 실용적 고려사항
vLLM ROCm 백엔드를 실제로 사용하려면 ROCm 드라이버 호환성 문제가 가장 먼저 해결되어야 할 과제다. 이는 AMD GPU 환경 전반에 해당하는 보편적 이슈로, vLLM의 ROCm 빌드는 특정 ROCm 버전에 강하게 결합되어 있어 드라이버 버전 불일치 시 설치 자체가 실패할 수 있다. ROCm 지원 GPU 목록과 커널 버전 매트릭스를 사전에 확인하는 것이 필수다.
.safetensors 직접 로드가 가능하다는 점은 HuggingFace PEFT/LoRA로 파인튜닝한 어댑터를 병합한 모델을 GGUF 재변환 없이 즉시 평가할 수 있다는 실용적 이점을 제공한다. 실험-평가 사이클에서 변환 단계를 제거할 수 있다.
한계 및 현실적 제약
현 시점에서 이 통합은 명확한 실험적 단계에 있다.
- 알려진 미완성 부분(rough edges): 공식 발표에서 “known rough edges”가 존재함을 명시했다. 구체적인 항목은 공개되지 않았으나, 모델 로딩 오류, 특정 아키텍처 미지원, 메모리 관리 불안정 등이 전형적인 초기 통합 문제다.
- ROCm 버전 의존성: vLLM의 ROCm 빌드는 특정 ROCm 버전에 강하게 결합되어 있어, 드라이버 버전 불일치 시 설치 자체가 실패할 수 있다.
- 성능 벤치마크 미공개: 현재 llama.cpp 대비 처리량(throughput), 지연(latency) 비교 데이터가 제공되지 않는다. 단일 사용자 로컬 실행 시나리오에서는 llama.cpp가 오히려 유리할 수 있다.
- 커뮤니티 의존적 로드맵: 개발팀이 “커뮤니티 피드백을 보고 어디까지 발전시킬지 결정하겠다”고 밝힌 만큼, 기능 안정화 일정이 불확실하다.
결론
vLLM ROCm의 Lemonade 통합은 AMD GPU 기반 로컬/온프레미스 LLM 서빙 생태계에 의미 있는 확장이다. .safetensors 직접 실행이라는 기술적 이점은 명확하며, llama.cpp와 동일한 CLI 추상화 레이어를 유지한다는 점에서 도입 장벽도 낮다.
그러나 프로덕션 적용 전에는 자체 환경에서의 안정성 검증이 선행되어야 한다. 현 단계에서의 실용적 활용 시나리오는 신규 모델 아키텍처의 빠른 프로토타이핑과 AMD GPU 환경에서의 파인튜닝 모델 직접 평가로 제한하는 것이 합리적이다.
출처: vLLM ROCm added to Lemonade as experimental backend | Lemonade 커뮤니티 발표 (Reddit)