헤르메스 에이전트 설치 가이드: 로컬·Docker·Slack 30분 완성 [2편]

헤르메스 에이전트 설치 방법을 단계별로 설명합니다. pip 설치부터 Ollama 로컬 모델, Docker 배포, Slack·Telegram 연동까지 30분 안에 팀 운용 환경을 구축하는 가이드입니다.
헤르메스 에이전트 설치 방법을 단계별로 설명합니다. pip 설치부터 Ollama 로컬 모델, Docker 배포, Slack·Telegram 연동까지 30분 안에 팀 운용 환경을 구축하는 가이드입니다.
헤르메스 에이전트(Hermes Agent)는 Nous Research가 출시한 오픈소스 자율 AI 에이전트로, 스킬 파일을 자동 생성해 쓸수록 빨라집니다. GitHub 14만 스타, OpenRouter 1위 달성 배경과 스킬 시스템·3계층 메모리 구조를 5편 시리즈로 정리합니다.

TL;DR AI가 똑똑해질수록 답변이 길어지고, 출력 토큰은 입력 토큰보다 4~6배 비싸 비용과 컨텍스트를 동시에 잡아먹는다. Caveman 프롬프트는 Claude에게 원시인처럼 짧게 말하라고 지시해 출력 토큰을 평균 65%, 최대 87% 절감한다. 플러그인 한 줄 설치로 적용, /caveman-compress로 CLAUDE.md까지 압축하면 입력 토큰도 46% 추가 절감된다. “AI한테 우가우가 시켰더니 토큰 87% 줄었다” SNS에서 이 한 줄이 퍼졌을 때 처음엔 … 더 읽기

TL;DR Claude Design은 2026년 4월 Anthropic이 출시한 Chat-to-Design 도구 — 대화 한 줄로 프로토타입·슬라이드·원페이저를 만든다. 코드베이스를 업로드하면 브랜드 색상·타이포그래피를 자동 학습, 이후 모든 결과물에 일관되게 적용된다. Pro 이상 플랜에 추가 비용 없이 포함, claude.ai/design에서 바로 접근 가능하다. 디자이너 없이 프로토타입을 만들어야 하는 상황 투자자 미팅 전날 밤, PM이 Figma를 열고 멈추는 건 한국 스타트업에서 흔한 … 더 읽기

Codex CLI 명령어 73개를 카테고리별로 정리했습니다. GPT-5.5 기반 설치부터 codex exec CI 자동화, 슬래시 커맨드, 샌드박스 설정까지 Claude Code와의 차이점을 실무 예시로 비교합니다.

로컬 LLM 1조 파라미터 실행 — 로컬 LLM 1조 파라미터 모델을 768GB Optane PMem + 12GB GPU로 실행하는 방법. MoE 아키텍처 활용, llama.cpp 설정, 메모리 계층화 전략을 단계별로 설명합니다.
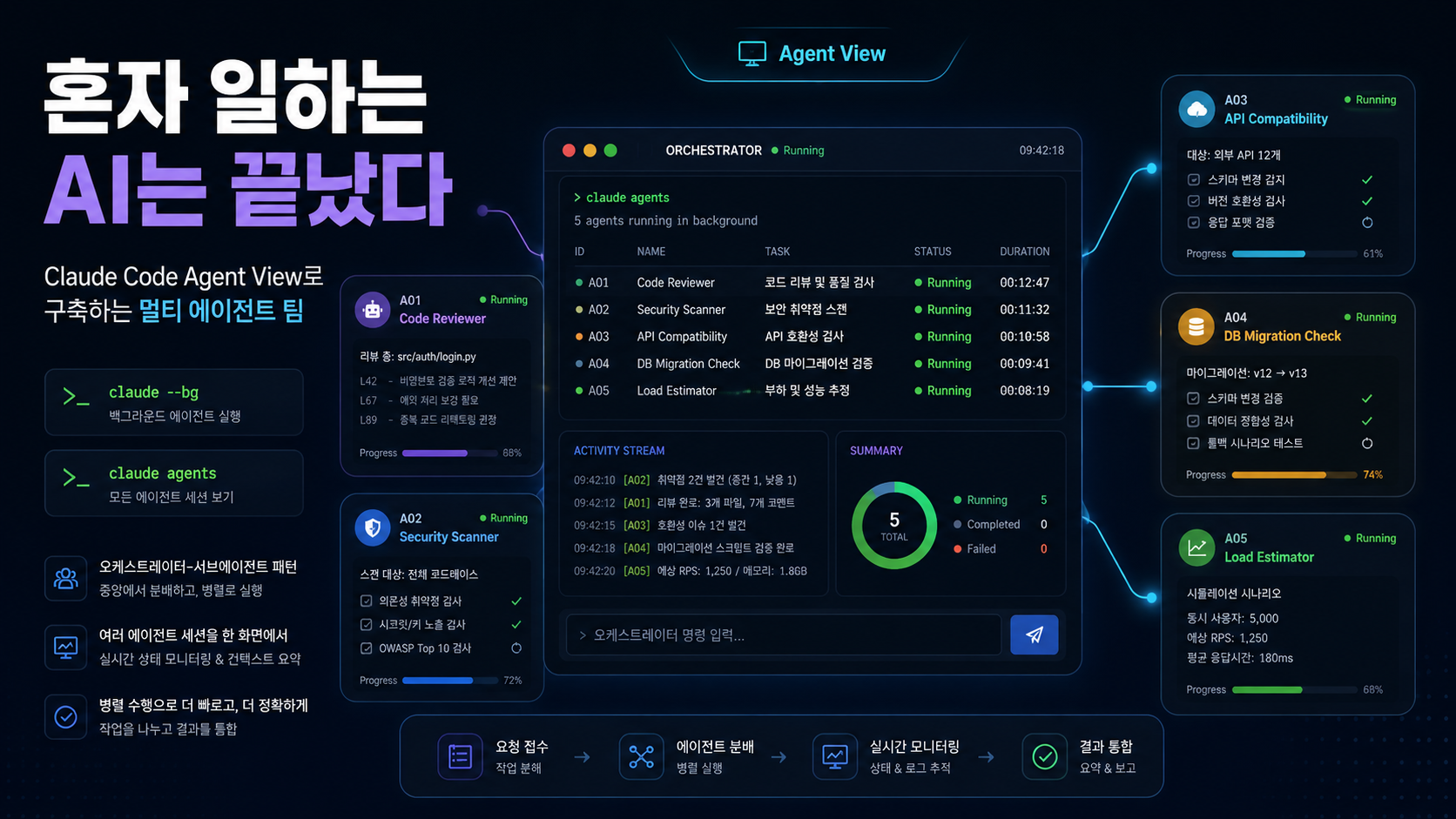
Claude Code의 Agent View(research preview)를 통해 여러 AI 에이전트를 동시 운영하는 법을 알아봅니다. 오케스트레이터 패턴 설계부터 MCP 연동, 모델별 비용 최적화까지 실전 가이드를 확인하세요.

로컬 LLM 32GB VRAM 비교 — 로컬 LLM 32GB VRAM 환경에서 Qwen3 35B A3B, Qwen3 27B, Gemma 4 26B, Nemotron 3 Nano 4개 모델을 코드 이해 태스크로 비교 분석. 장문맥 처리 아키텍처와 실제 성능 평가.

DeepSeek V4 Pro 로컬 추론을 단일 워크스테이션에서 성공적으로 수행한 사례를 분석합니다. llama.cpp CUDA 빌드와 Q4_K_M 양자화로 89.4GB VRAM에서 구동하는 설치 방법과 성능 벤치마크를 확인하세요.

Star Elastic 추론 제어는 NVIDIA가 공개한 단일 체크포인트 기반 스펙트럼 추론 기술입니다. Gumbel-Softmax 라우터로 30B, 23B, 12B 모델을 제로샷 슬라이싱하여 사고·답변 단계별 동적 용량 할당을 구현하는 방법을 알아보세요.